1. UML类图 面向对象设计主要就是使用UML的类图,类图用于描述系统中所包含的类以及它们之间的相互关系,帮助人们简化对系统的理解,它是系统分析和设计阶段的重要产物,也是系统编码和测试的重要模型依据。 下面基于C++这门语言给大家讲一下UML类图的画法。
1.1 类的UML画法 类(class / struct)封装了数据和行为,是面向对象的重要组成部分,它是具有相同属性、操作、关系的对象集合的总称。 在系统中,每个类都具有一定的职责,职责指的是类要完成什么样子的功能,要承担什么样子的义务。一个类可以有多种职责,但是设计得好的类一般只有一种职责。
比如,我现在定义了猎人类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Hunter { public : int m_age = 32 ; static int m_times; string getName () { return m_name; } void setName (string name) { m_name = name; } void goHunting () { aiming (); shoot (); } static void saySorry () { string count = to_string (m_times); cout << "Say sorry to every animal " + count + " times!" << endl; } protected : string m_name = "Jack" ; void aiming () { cout << "使用" + m_gunName + "瞄准猎物..." << endl; } private : string m_gunName = "AK-47" ; void shoot () { cout << "使用" + m_gunName + "射击猎物..." << endl; } }; int Hunter::m_times = 3 ;
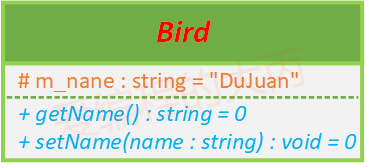
上面这个类对应的类图应该是这样的:
可以看到该图分为上中下三部分:上层是类名,中间层是属性(类的成员变量),下层是方法(类的成员函数)。
可见性:+ 表示public、# 表示protected、- 表示private、__(下划线)表示static
属性的表示方式:【可见性】【属性名称】:【类型】= { 缺省值,可选 }
方法的表示方式:【可见性】【方法名称】(【参数名 : 参数类型,……】):【返回值类型】
如果我们定义的类是一个抽象类(类中有纯虚函数),在画UML类图的时候,类名需要使用斜体显示。
在使用UML画类图的时候,虚函数的表示方跟随类名,也就是使用斜体 ,如果是纯虚函数则需要在最后给函数指定=0。
1.2 类与类之间的关系 1.2.1 继承关系 继承也叫作泛化(Generalization),用于描述父子类之间的关系,父类又称为基类或者超类,子类又称作派生类。在UML中,泛化关系用带空心三角形的实线来表示。
关于继承关系一共有两种:普通继承关系和抽象继承关系,但是不论哪一种表示继承关系的线的样式是不变的。
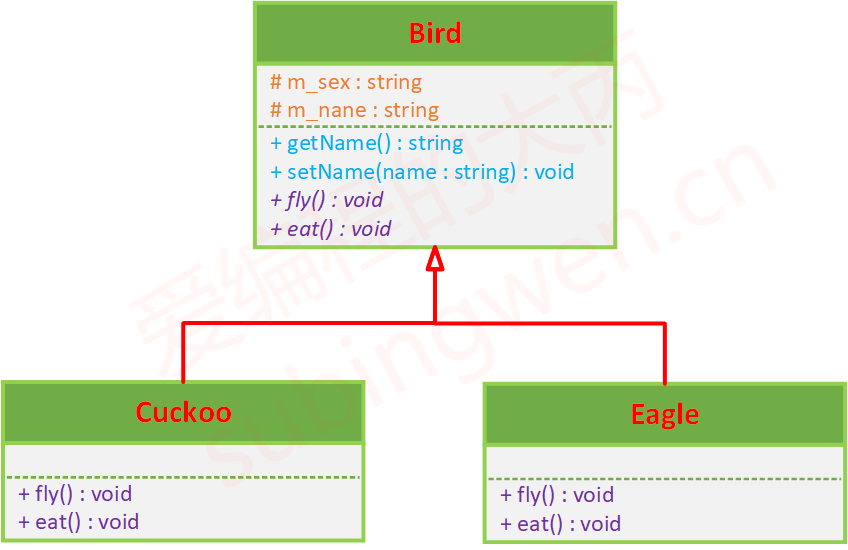
假如现在我定义了一个父类(Bird)和两个子类(Cuckoo、Eagle):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Bird { public : string getName () { return m_name; } void setName (string name) { m_name = name; } virtual void fly () virtual void eat () protected : string m_sex; string m_name; }; class Cuckoo : public Bird{ public : void fly () override { cout << "我拍打翅膀飞行..." << endl; } void eat () override { cout << "我喜欢吃肉肉的小虫子..." << endl; } }; class Eagle : public Bird{ public : void fly () override { cout << "我展翅翱翔..." << endl; } void eat () override { cout << "我喜欢吃小动物..." << endl; } };
使用UML表示上述这种关系应当是:
父类Bird中的fly()和eat()是虚函数,它有两个子类Cuckoo和Eagle在这两个子类中重写了父类的虚函数,在使用带空心三角的实现表示继承关系的时候,有空心三角的一端指向父类,另一端连接子类。
1.2.2 关联关系 关联(Assocition)关系是类与类之间最常见的一种关系,它是一种结构化的关系,表示一个对象与另一个对象之间有联系,如汽车和轮胎、师傅和徒弟、班级和学生等。在UML类图中,用(带接头或不带箭头的)实线连接有关联关系的类。在C++中这种关联关系在类中是这样体现的,通常将一个类的对象作为另一个类的成员变量。
类之间的关联关系有三种,分别是:单向关联、双向关联、自关联。下面逐一给大家进行介绍。
单向关联关系 单向关联指的是关联只有一个方向,比如每个孩子(Child)都拥有一个父亲(Parent),其代码实现为:
1 2 3 4 5 6 7 8 9 class Parent { }; class Child { private : Parent m_father; };
通过UML来说描述这两个类之间的关系,如下图:
如果是单向关联,使用的连接线是带单向箭头的实线 , 哪个类作为了当前类的成员变量,那么箭头就指向哪个类。在这个例子中 Parent 类 作为了Child 类的成员变量,因此箭头端应该指向Parent 类,另一端连接 Child 类。
双向关联关系 现实生活中每个孩子都有父母,每个父母同样有自己的孩子,如果想要通过类来描述这样的亲情关系,代码如下:
1 2 3 4 5 6 7 8 9 10 11 class Parent { private : Child m_son; }; class Child { private : Parent m_father; };
通过UML来说描述这两个类之间的关系,如下图:
在画UML类图的时候,一般使用没有箭头的实线来连接有双向关联关系的两个类,这两个类的对象分别作为了对方类的成员变量。
有些UML绘图软件使用的是带双向箭头的实线来表示双向关联关系。
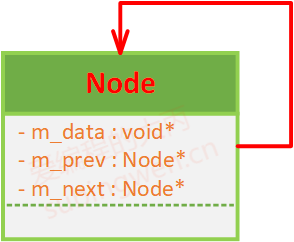
自关联关系 自关联指的就是当前类中包含一个自身类型的对象成员,这在链表中非常常见,单向链表中都会有一个指向自身节点类型的后继指针成员,而双向链表中会包含一个指向自身节点类型的前驱指针和一个指向自身节点类型的后继指针。就以双向链表节点类为例,它的C++写法为:
1 2 3 4 5 6 7 class Node { private : void * m_data; Node* m_prev; Node* m_next; };
对应的UML类图应当是:
一般使用带箭头的实线来描述自关联关系,我中有我,独角戏。
有些UML绘图软件表示类与类的关联关系,使用的就是一条实线,没有箭头。
1.2.3 聚合关系 聚合(Aggregation)关系表示整体 与部分 的关系。在聚合关系中,成员对象是整体的一部分,但是成员对象可以脱离整体对象独立存在。 在UML中,聚合关系用带空心菱形的直线表示,下面举两个聚合关系的例子:
汽车(Car)与 引擎(Engine)、轮胎(Wheel)、车灯(Light)
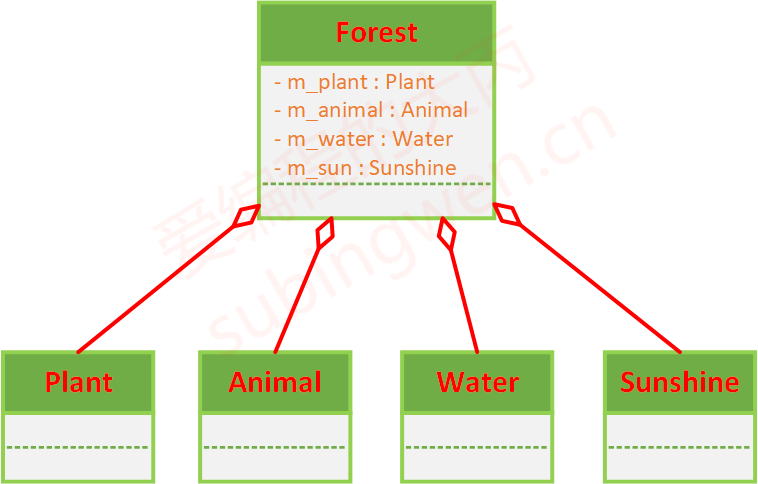
森林(Forest)与 植物(Plant)、动物(Animal)、水(Water)、阳光(Sunshine)
以森林为例,对应的C++类的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Plant { }; class Animal { }; class Water { }; class Sunshine { }; class Forest { public : Forest (Plant p, Animal a, Water w, Sunshine s) : m_plant (p),m_animal (a),m_water (w),m_sun (s) { } private : Plant m_plant; Animal m_animal; Water m_water; Sunshine m_sun; };
对应的UML类图为:
代码实现聚合关系,成员对象通常以构造方法、Setter方法的方式注入到整体对象之中,因为成员对象可以脱离整体对象独立存在。
表示聚合关系的线,有空心菱形的一端指向整体对象,另一端连接局部对象(有些UML绘图软件在这一端还带一个箭头)。
1.2.4 组合关系 组合(Composition)关系也表示的是一种整体和部分的关系 ,但是在组合关系中整体对象可以控制成员对象的生命周期,一旦整体对象不存在,成员对象也不存在,整体对象和成员对象之间具有同生共死的关系。
在UML中组合关系用带实心菱形的直线表示 ,下面举两个组合关系的例子:
头(Head)和 嘴巴(Mouth)、鼻子(Nose)、耳朵(Ear)、眼睛(Eye)
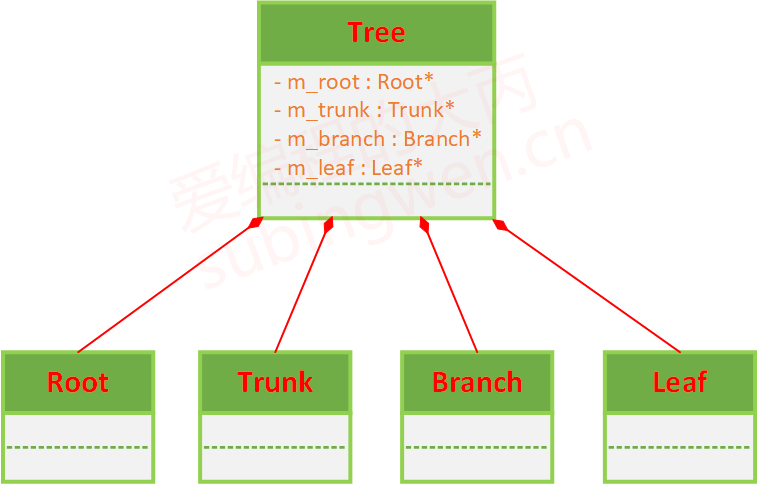
树(Tree)和 树根(Root)、树干(Trunk)、树枝(Branch)、树叶(Leaf)
以树为例,对应的C++类的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Root { }; class Trunk { }; class Branch { }; class Leaf { }; class Tree { public : Tree () { m_root = new Root; m_trunk = new Trunk; m_branch = new Branch; m_leaf = new Leaf; } ~Tree () { delete m_root; delete m_trunk; delete m_branch; delete m_leaf; } private : Root* m_root; Trunk* m_trunk; Branch* m_branch; Leaf* m_leaf; };
其UML的表示方法为:
代码实现组合关系,通常在整体类的构造方法中直接实例化成员类 ,因为组合关系的整体和部分是共生关系,整体的实例对象被析构的时候它的子对象也会一并被析构。如果通过外部注入,即使整体不存在了,部分还是存在的,这样的话就变成聚合关系了。
1.2.5 依赖关系 依赖(Dependency)关系是一种使用关系 ,特定事物的改变有可能会影响到使用该事物的其他事物,在需要表示一个事物使用另一个事物时使用依赖关系,大多数情况下依赖关系体现在某个类的方法使用另一个类的对象作为参数。
在UML中,依赖关系用带箭头的虚线表示,由依赖的一方指向被依赖的一方 ,下面举两个依赖关系的例子:
驾驶员(Driver)开车,需要将车(Car)对象作为参数传递给 Driver 类的drive()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Car { public : void move () }; class Driver { public : void drive (Car car) { car.move (); } };
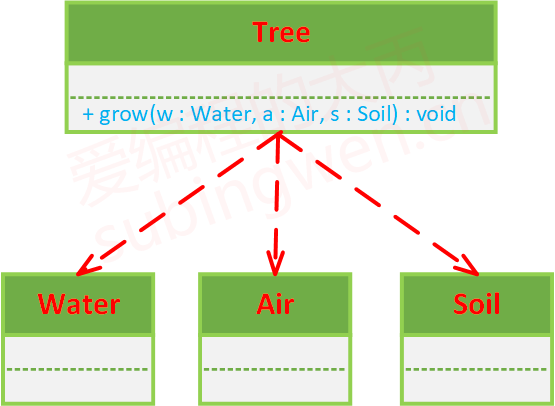
树木(Tree)的生长,需要将空气(Air)、水(Water)、土壤(Soil)对象作为参数传递给 Tree 类的 grow()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Water { }; class Air { }; class Soil { }; class Tree { public : void grow (Water w, Air a, Soil s) { cout << "借助 w 中的水分, s 中的养分和 a 中的二氧化碳, 我就可以茁壮成长了" ; } };
关于树木这个类,它对应的UML类图为:
依赖关系通常通过三种方式来实现:
将一个类的对象作为另一个类中方法的参数
在一个类的方法中将另一个类的对象作为其对象的局部变量
在一个类的方法中调用另一个类的静态方法
类之间的关系强弱顺序是这样的:继承(泛化) > 组合 > 聚合 > 关联 > 依赖。
1.2.6 关联关系、聚合关系、组合关系之间的区别 从上文可以看出,关联关系、聚合关系和组合关系三者之间比较相似,最后就来总结一下这三者之间的区别:
关联和聚合的区别主要在于语义上:关联的两个对象之间一般是平等的,聚合则一般是不平等的。
聚合和组合的区别则在语义和实现上都有差别:
组合的两个对象之间生命周期有很大的关联,被组合的对象在组合对象创建的同时或者创建之后创建在组合对象销毁之前销毁,聚合则无需考虑这些事情。
一般来说被组合对象不能脱离组合对象独立存在,而且也只能属于一个组合对象,聚合则不一样,被聚合的对象可以属于多个聚合对象。
最后,再举例子来描述一下这三种关系:
朋友之间属于关联关系,因为这种关系是平等的,关联关系只是用于表示两个对象之间的一种简单的联系而已。
图书馆看书的时候,人和书属于聚合关系。书是可以独立存在的,而且书不仅可以属于自己,也可以属于别人。
人和自己的心脏属于组合关系,因为心脏不能脱离人体而独自存在。
不过,实际应用中,这三种关系的界限划分其实没有那么清楚,有些时候我们会感觉组合和聚合没什么区别,所以,在设计的时候没必要死抠细节,只要能够利用对象之间的关系设计出可行的解决方案即可。
2. 设计模式三原则 我们在进行程序设计的时候,要尽可能地保证程序的可扩展性、可维护性和可读性,所以需要使用一些设计模式,这些设计模式都遵循了以下三个原则,下面来依次为大家介绍。
2.1 单一职责原则 C++面向对象三大特性之一的封装指的就是将单一事物抽象出来组合成一个类,所以我们在设计类的时候每个类中处理的是单一事物而不是某些事物的集合。
设计模式中所谓的单一职责原则,就是对一个类而言,应该仅有一个引起它变化的原因,其实就是将这个类所承担的职责单一化
如果一个类承担的职责过多,就等于把这些职责耦合到了一起,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致设计变得脆弱,当变化发生时,设计会遭受到意想不到的破坏。
一个单一职责的类,这个类被追加了一些其他的职责,这个类没能完成开始时的预期任务,就此废掉了。
软件设计真正要做的事情就是,发现根据需求发现职责,并把这些职责进行分离,添加新的类,给当前类减负,越是这样项目才越容易维护。
2.2 开放封闭原则 开放 – 封闭原则说的是软件实体(类、模块、函数等)可以扩展,但是不可以修改。也就是说对于扩展是开放的,对于修改是封闭的。
该原则是程序设计的一种理想模式,在很多情况下无法做到完全的封闭。但是作为设计人员,应该能够对自己设计的模块在哪些位置产生何种变化了然于胸,因此需要在这些位置创建抽象类来隔离以后发生的这些同类变化(其实就是对多态的应用,创建新的子类并重写父类虚函数,用以更新处理动作)。
此处的抽象类,其实并不等价与C++中完全意义上是抽象类(需要有纯虚函数),这里所说的抽象类只需要包含虚函数(纯虚函或非纯虚函数)能够实现多态即可。
草帽团船长路飞从出海到现在一共召集了9个伙伴,这些伙伴在船上的职责都是不一样的,有音乐家、船工、舵手、航海士、剑士、考古学家、狙击手、厨师、船医,作为船长没有要求自己学习这些船员的技能【对自己来说是封闭的 】,而是提出了伙伴的概念【这就是一个可变的抽象 】,最终找到了优秀的伙伴加入【对外是开放的,每个伙伴都是这个抽象的具体实现,但他们的技能又有所不同 】,事实证明这样做是对的,如果反其道而行之,不仅违背了开放封闭原则,也违背了单一职责原则。
开放 – 封闭原则是面向对象设计的核心所在,这样可以给我们设计出的程序带来巨大的好处,使其可维护性、可扩展性、可复用性、灵活性更好。
2.3 依赖倒转原则 关于依赖倒转原则,对应的是两条非常抽象的描述:
1. 高层模块不应该依赖低层模块,两个都应该依赖抽象。 抽象不应该依赖细节,细节应该依赖抽象。
高层模块:可以理解为上层应用,就是业务层的实现
低层模块:可以理解为底层接口,比如封装好的API、动态库等
抽象:指的就是抽象类或者接口,在C++中没有接口,只有抽象类
先举一个高层模块依赖低层模块的例子:
低层使用的是MySql的数据库接口,高层基于这套接口对数据库表进行了添删查改,实现了对业务层数据的处理。而后由于某些原因,要存储到数据库的数据量暴增,所以更换了Oracle数据库,由于低层的数据库接口变了,高层代码的数据库操作部分是直接调用了低层的接口,因此也需要进行对应的修改,无法实现对高层代码的直接复用。
通过上面的例子可以得知,当依赖的低层模块变了就会牵一发而动全身,如果这样设计项目架构,其工作量无疑是很重的。
如果要搞明白这个案例的解决方案以及抽象和细节之间的依赖关系,需要先了解另一个原则 — 里氏代换原则。
里氏代换原则 所谓的里氏代换原则就是子类类型必须能够替换掉它们的父类类型。
关于这个原理的应用其实也很常见,比如在Qt中,所有窗口类型的类的构造函数都有一个QWidget*类型的参数(QWidget 类是所有窗口的基类),通过这个参数指定当前窗口的父对象。虽然参数是窗口类的基类类型,但是我们在给其指定实参的大多数时候,指定的都是子类的对象,其实也就是相当于使用子类类型替换掉了它们的父类类型。
这个原则的要满足的第一个条件就是继承,其次还要求子类继承的所有父类的属性和方法对于子类来说都是合理的。关于这个是否合理下面举个栗子:
比如,对于哺乳动物来说都是胎生,但是有一种特殊的存在就是鸭嘴兽,它虽然是哺乳动物,但是是卵生。
如果我们设计了两个类:哺乳动物类和鸭嘴兽类,此时能够让鸭嘴兽类继承哺乳动物类吗?答案肯定是否定的,因为如果我们这么做了,鸭嘴兽就继承了胎生属性,这个属性和它自身的情况是不匹配的。如果想要遵循里氏代换原则,我们就不能让着两个类有继承关系。
如果我们创建了其它 的胎生的哺乳动物类,那么它们是可以继承哺乳动物这个类的,在实际应用中就可以使用子类替换掉父类,同时功能也不会受到影响,父类实现了复用,子类也能在父类的基础上增加新的行为,这就是里氏代换原则。
上面在讲依赖倒转原则的时候说过,抽象不应该依赖细节,细节应该依赖抽象。也就意味着我们应该对细节进行封装,在C++中就是将其放到一个抽象类中(C++中没有接口,不能像Java一样封装成接口),每个细节就相当于上面例子中的哺乳动物的一个特性,这样一来这个抽象的哺乳动物类就成了项目架构中高层和低层的桥梁,将二者整合到一起。
基于依赖倒转原则将项目的结构换成上图的这种模式之后,低层模块发生变化,对应高层模块是没有任何影响的,这样程序猿的工作量降低了,代码也更容易维护(说白了,依赖倒转原则就是对多态的典型应用 )。
3. 单例模式 3.1 巴基的订单 巴基有一个账本用于记录下单者信息,下单者的需求以及下单的时间,然后根据下单的先后顺序选择合适的人手进行派单。这个账本其实就相当于一个任务队列:
有一定的容量,可以存储任务
按照下单的先后顺序存储并处理任务 – 典型的队列特性:先进先出
对于巴基来说把所有的订单全部记录到一个账本上就够了,如果将其平移到项目中,也就意味着应用程序在运行过程中存储任务的任务队列一个足矣,弄太多反而冗余,不太好处理了。
在一个项目中,全局范围内,某个类的实例有且仅有一个,通过这个唯一实例向其他模块提供数据的全局访问,这种模式就叫单例模式。单例模式的典型应用就是任务队列。
3.2 独生子女 如果使用单例模式,首先要保证这个类的实例有且仅有一个,也就是说这个对象是独生子女,如果我们实施计划生育只生一个孩子,不需要也不能给再他增加兄弟姐妹。因此,就必须采取一系列的防护措施。对于类来说以上描述同样适用。涉及一个类多对象操作的函数有以下几个:
构造函数:创建一个新的对象拷贝构造函数:根据已有对象拷贝出一个新的对象拷贝赋值操作符重载函数:两个对象之间的赋值
为了把一个类可以实例化多个对象的路堵死,可以做如下处理:
构造函数私有化,在类内部只调用一次,这个是可控的。
由于使用者在类外部不能使用构造函数,所以在类内部创建的这个唯一的对象必须是静态的,这样就可以通过类名来访问了,为了不破坏类的封装,我们都会把这个静态对象的访问权限设置为私有的。 在类中只有它的静态成员函数才能访问其静态成员变量,所以可以给这个单例类提供一个静态函数用于得到这个静态的单例对象。
拷贝构造函数私有化或者禁用(使用 = delete)
拷贝赋值操作符重载函数私有化或者禁用(从单例的语义上讲这个函数已经毫无意义,所以在类中不再提供这样一个函数,故将它也一并处理一下。)
由于单例模式就是给类创建一个唯一的实例对象,所以它的UML类图是很简单的:
因此,定义一个单例模式的类的示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 class Singleton { public : Singleton (const Singleton& obj) = delete ; Singleton& operator =(const Singleton& obj) = delete ; static Singleton* getInstance () private : Singleton () = default ; static Singleton* m_obj; };
在实现一个单例模式的类的时候,有两种处理模式:
3.3 饿汉模式 饿汉模式就是在类加载的时候立刻进行实例化,这样就得到了一个唯一的可用对象。关于这个饿汉模式的类的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { return m_taskQ; } private : TaskQueue () = default ; static TaskQueue* m_taskQ; }; TaskQueue* TaskQueue::m_taskQ = new TaskQueue; int main () TaskQueue* obj = TaskQueue::getInstance (); }
在第17行,定义这个单例类的时候,就把这个静态的单例对象创建出来了。当使用者通过getInstance()获取这个单例对象的时候,它已经被准备好了。
注意事项:类的静态成员变量在使用之前必须在类的外部进行初始化才能使用。
3.4 懒汉模式 懒汉模式是在类加载的时候不去创建这个唯一的实例,而是在需要使用的时候再进行实例化。
3.4.1 懒汉模式类的定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { if (m_taskQ == nullptr ) { m_taskQ = new TaskQueue; } return m_taskQ; } private : TaskQueue () = default ; static TaskQueue* m_taskQ; }; TaskQueue* TaskQueue::m_taskQ = nullptr ;
在调用getInstance()函数获取单例对象的时候,如果在单线程情况下是没有什么问题的,如果是多个线程,调用这个函数去访问单例对象就有问题了。假设有三个线程同时执行了getInstance()函数,在这个函数内部每个线程都会new出一个实例对象。此时,这个任务队列类的实例对象不是一个而是3个,很显然这与单例模式的定义是相悖的。
3.4.2 线程安全问题 双重检查锁定 对于饿汉模式是没有线程安全问题的,在这种模式下访问单例对象的时候,这个对象已经被创建出来了。 要解决懒汉模式的线程安全问题,最常用的解决方案就是使用互斥锁。可以将创建单例对象的代码使用互斥锁锁住,处理代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { m_mutex.lock (); if (m_taskQ == nullptr ) { m_taskQ = new TaskQueue; } m_mutex.unlock (); return m_taskQ; } private : TaskQueue () = default ; static TaskQueue* m_taskQ; static mutex m_mutex; }; TaskQueue* TaskQueue::m_taskQ = nullptr ; mutex TaskQueue::m_mutex;
在上面代码的10~13 行这个代码块被互斥锁锁住了,也就意味着不论有多少个线程,同时执行这个代码块的线程只能是一个(相当于是严重限行了,在重负载情况下,可能导致响应缓慢)。我们可以将代码再优化一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { if (m_taskQ == nullptr ) { m_mutex.lock (); if (m_taskQ == nullptr ) { m_taskQ = new TaskQueue; } m_mutex.unlock (); } return m_taskQ; } private : TaskQueue () = default ; static TaskQueue* m_taskQ; static mutex m_mutex; }; TaskQueue* TaskQueue::m_taskQ = nullptr ; mutex TaskQueue::m_mutex;
改进的思路就是在加锁、解锁的代码块外层有添加了一个if判断(第9行),这样当任务队列的实例被创建出来之后,访问这个对象的线程就不会再执行加锁和解锁操作了(只要有了单例类的实例对象,限行就解除了),对于第一次创建单例对象的时候线程之间还是具有竞争关系,被互斥锁阻塞。上面这种通过两个嵌套的 if 来判断单例对象是否为空的操作就叫做双重检查锁定。
双重检查锁定的问题 假设有两个线程A、B,当线程A 执行到第 8 行时在线程A中 TaskQueue 实例对象 被创建,并赋值给 m_taskQ。
1 2 3 4 5 6 7 8 9 10 11 12 13 static TaskQueue* getInstance () if (m_taskQ == nullptr ) { m_mutex.lock (); if (m_taskQ == nullptr ) { m_taskQ = new TaskQueue; } m_mutex.unlock (); } return m_taskQ; }
但是实际上 m_taskQ = new TaskQueue; 在执行过程中对应的机器指令可能会被重新排序。正常过程如下:
第一步:分配内存用于保存 TaskQueue 对象。
第二步:在分配的内存中构造一个 TaskQueue 对象(初始化内存)。
第三步:使用 m_taskQ 指针指向分配的内存。
但是被重新排序以后执行顺序可能会变成这样:
第一步:分配内存用于保存 TaskQueue 对象。
第二步:使用 m_taskQ 指针指向分配的内存。
第三步:在分配的内存中构造一个 TaskQueue 对象(初始化内存)。
这样重排序并不影响单线程的执行结果,但是在多线程中就会出问题。如果线程A按照第二种顺序执行机器指令,执行完前两步之后失去CPU时间片被挂起了,此时线程B在第3行处进行指针判断的时候m_taskQ 指针是不为空的,但这个指针指向的内存却没有被初始化,最后线程 B 使用了一个没有被初始化的队列对象就出问题了(出现这种情况是概率问题,需要反复的大量测试问题才可能会出现)。
在C++11中引入了原子变量atomic,通过原子变量可以实现一种更安全的懒汉模式的单例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { TaskQueue* queue = m_taskQ.load (); if (queue == nullptr ) { lock_guard<mutex> locker (m_mutex) ; queue = m_taskQ.load (); if (queue == nullptr ) { queue = new TaskQueue; m_taskQ.store (queue); } } return queue; } void print () { cout << "hello, world!!!" << endl; } private : TaskQueue () = default ; static atomic<TaskQueue*> m_taskQ; static mutex m_mutex; }; atomic<TaskQueue*> TaskQueue::m_taskQ; mutex TaskQueue::m_mutex; int main () TaskQueue* queue = TaskQueue::getInstance (); queue->print (); return 0 ; }
上面代码中使用原子变量atomic的store() 方法来存储单例对象,使用load() 方法来加载单例对象。在原子变量中这两个函数在处理指令的时候默认的原子顺序是memory_order_seq_cst(顺序原子操作 - sequentially consistent),使用顺序约束原子操作库,整个函数执行都将保证顺序执行,并且不会出现数据竞态(data races),不足之处就是使用这种方法实现的懒汉模式的单例执行效率更低一些。
静态局部对象 在实现懒汉模式的单例的时候,相较于双重检查锁定模式有一种更简单的实现方法并且不会出现线程安全问题,那就是使用静态局部局部对象,对应的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { static TaskQueue taskQ; return &taskQ; } void print () { cout << "hello, world!!!" << endl; } private : TaskQueue () = default ; }; int main () TaskQueue* queue = TaskQueue::getInstance (); queue->print (); return 0 ; }
在程序的第 9、10 行定义了一个静态局部队列对象,并且将这个对象作为了唯一的单例实例。使用这种方式之所以是线程安全的,是因为在C++11标准中有如下规定,并且这个操作是在编译时由编译器保证的:
如果指令逻辑进入一个未被初始化的声明变量,所有并发执行应当等待该变量完成初始化。
最后总结一下懒汉模式和饿汉模式的区别:
懒汉模式的缺点是在创建实例对象的时候有安全问题,但这样可以减少内存的浪费(如果用不到就不去申请内存了)。饿汉模式则相反,在我们不需要这个实例对象的时候,它已经被创建出来,占用了一块内存。对于现在的计算机而言,内存容量都是足够大的,这个缺陷可以被无视。
3.5 写一个任务队列 如果想给巴基的账本升级成一个应用程序,首要任务就是设计一个单例模式的任务队列,那么就需要赋予这个类一些属性和方法:
属性:
存储任务的容器,这个容器可以选择使用STL中的队列(queue)
互斥锁,多线程访问的时候用于保护任务队列中的数据
方法:主要是对任务队列中的任务进行操作
任务队列中任务是否为空
往任务队列中添加一个任务
从任务队列中取出一个任务
从任务队列中删除一个任务
根据分析,就可以把这个饿汉模式的任务队列的单例类定义出来了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 #include <iostream> #include <queue> #include <mutex> #include <thread> using namespace std;class TaskQueue { public : TaskQueue (const TaskQueue& obj) = delete ; TaskQueue& operator =(const TaskQueue& obj) = delete ; static TaskQueue* getInstance () { return &m_obj; } bool isEmpty () { lock_guard<mutex> locker (m_mutex) ; bool flag = m_taskQ.empty (); return flag; } void addTask (int data) { lock_guard<mutex> locker (m_mutex) ; m_taskQ.push (data); } int takeTask () { lock_guard<mutex> locker (m_mutex) ; if (!m_taskQ.empty ()) { return m_taskQ.front (); } return -1 ; } bool popTask () { lock_guard<mutex> locker (m_mutex) ; if (!m_taskQ.empty ()) { m_taskQ.pop (); return true ; } return false ; } private : TaskQueue () = default ; static TaskQueue m_obj; queue<int > m_taskQ; mutex m_mutex; }; TaskQueue TaskQueue::m_obj; int main () thread t1 ([]() { TaskQueue* taskQ = TaskQueue::getInstance(); for (int i = 0 ; i < 100 ; ++i) { taskQ->addTask(i + 100 ); cout << "+++push task: " << i + 100 << ", threadID: " << this_thread::get_id() << endl; this_thread::sleep_for(chrono::milliseconds(500 )); } }) thread t2 ([]() { TaskQueue* taskQ = TaskQueue::getInstance(); this_thread::sleep_for(chrono::milliseconds(100 )); while (!taskQ->isEmpty()) { int data = taskQ->takeTask(); cout << "---take task: " << data << ", threadID: " << this_thread::get_id() << endl; taskQ->popTask(); this_thread::sleep_for(chrono::seconds(1 )); } }) t1.join (); t2.join (); }
在上面的程序中有以下几点需要说明一下:
正常情况下,任务队列中的任务应该是一个函数指针(这个指针指向的函数中有需要执行的任务动作),此处进行了简化,用一个整形数代替了任务队列中的任务。
任务队列中的互斥锁保护的是单例对象的中的数据也就是任务队列中的数据,上面所说的线程安全指的是在创建单例对象的时候要保证这个对象只被创建一次,和此处完全是两码事儿,需要区别看待。
在main()函数中创建了两个子线程t1线程的处理动作是往任务队列中添加任务,t2线程的处理动作是从任务队列中取任务,为了保证能够取出所有的任务,此处需要让t2线程的执行晚并且慢一些。
4. 简单工厂模式 4.1 工厂模式的特点
实现有成本【构造一个对象有时候需要经历一个非常复杂的操作流程,既然麻烦那索性就不干了。】
有需求下单就行,只需关心结果,无需关心过程【实现了解耦合 】。
出了问题,自己无责任,售后直接找明哥【便于维护 】。
在程序设计中,这种模式就叫做工厂模式,工厂生成出的产品就是某个类的实例,也就是对象。关于工厂模式一共有三种,分别是:简单工厂模式、工厂模式、抽象工厂模式。
通过上面人造恶魔果实的例子,我们能够了解到,不论使用哪种工厂模式其主要目的都是实现类与类之间的解耦合,这样我们在创建对象的时候就变成了拿来主义,使程序更加便于维护。
基于简单工厂模式去创建对象的时候,需要提供一个工厂类,专门用于生产需要的对象,这样关于对象的创建操作就被剥离出去了。
简单工厂模式相关类的创建和使用步骤如下:
创建一个新的类, 可以将这个类称之为工厂类。对于简单工厂模式来说,需要的工厂类只有一个。
在这个工厂类中添加一个公共的成员函数,通过这个函数来创建我们需要的对象,关于这个函数一般将其称之为工厂函数。
关于使用,首先创建一个工厂类对象,然后通过这个对象调用工厂函数,这样就可以生产出一个指定类型的实例对象了。
4.2 生产的产品 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class SheepSmile { public : void transform () { cout << "变成人兽 -- 山羊人形态..." << endl; } void ability () { cout << "将手臂变成绵羊角的招式 -- 巨羊角" << endl; } }; class LionSmile { public : void transform () { cout << "变成人兽 -- 狮子人形态..." << endl; } void ability () { cout << "火遁· 豪火球之术..." << endl; } }; class BatSmile { public : void transform () { cout << "变成人兽 -- 蝙蝠人形态..." << endl; } void ability () { cout << "声纳引箭之万剑归宗..." << endl; } };
不论是吃了那种恶魔果实,获得了相应的能力之后,可以做的事情大体是相同的,那就是形态变化transform() 和 使用果实能力alility()。
另外,生产这些恶魔果实的时候可能需要极其复杂的参数,在此就省略了【也就是说这些类的构造函数的参数在此被省略了 】。
4.3 如何生产 如果想要生产出这些恶魔果实,可以先创建一个工厂类,然后再给这个工厂类添加一个工厂函数,又因为我们要生成三种不同类型的恶魔果实,所以可以给工厂函数添加一个参数,用以控制当前要生产的是哪一类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 enum class Type :char {SHEEP, LION, BAT};class SmileFactory { public : enum class Type :char {SHEEP, LION, BAT}; SmileFactory () {} ~SmileFactory () {} void * createSmile (Type type) { void * ptr = nullptr ; switch (type) { case Type::SHEEP: ptr = new SheepSmile; break ; case Type::LION: ptr = new LionSmile; break ; case Type::BAT: ptr = new BatSmile; break ; default : break ; } return ptr; } }; int main () SmileFactory* factory = new SmileFactory; BatSmile* batObj = (BatSmile*)factory->createSmile (Type::BAT); return 0 ; }
关于恶魔果实的类型,上面的类中用到了强类型枚举(C++11新特性),增强了代码的可读性,并且将枚举元素设置为了char类型,节省了内存。
函数createSmile(Type type)的返回值是void*类型,这样处理主要是因为每个case 语句创建出的对象类型是不一样的,为了实现兼容,故此这样处理。
得到函数createSmile(Type type)的返回值之后,还需要将其转换成实际的类型,处理起来还是比较繁琐的。
关于工厂函数的返回值,在C++中还有一种更好的解决方案,就是使用多态。如果想要实现多态,需要满足三个条件:
类和类之间有继承关系。 父类中有虚函数,并且在子类中需要重写这些虚函数。 使用父类指针或引用指向子类对象。
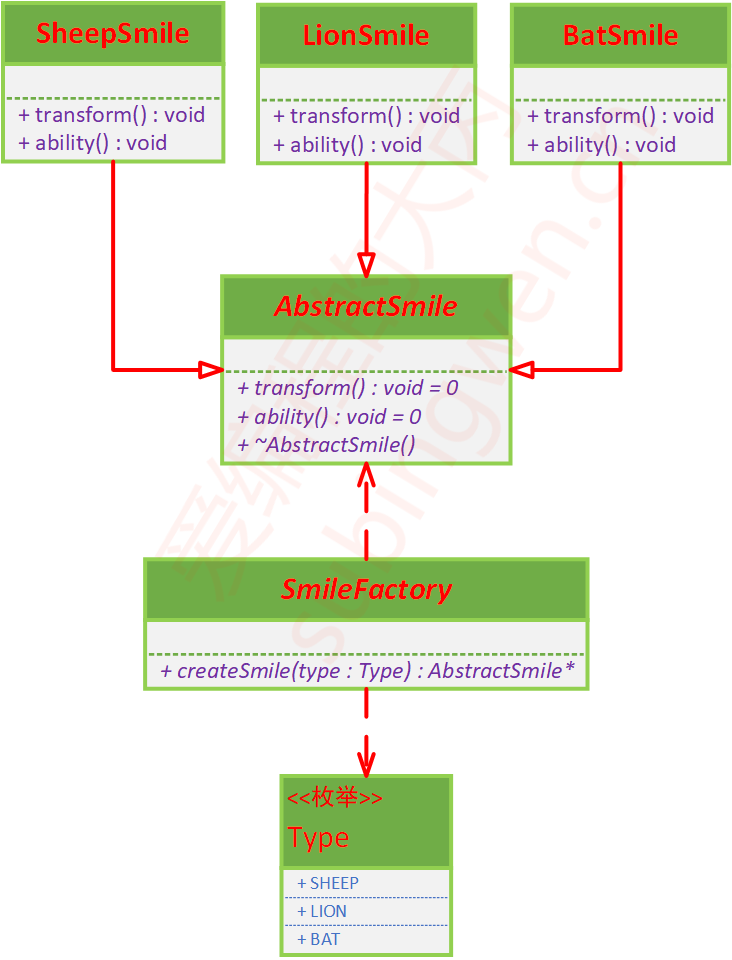
所以,我们需要给人造恶魔果实提供一个基类,然后让上边的三个类SheepSmile、LionSmile、BatSmile作为子类继承这个基类。根据分析我们就有画出简单工厂模式的UML类图了:
根据UML类图,编写出的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include <iostream> using namespace std;class AbstractSmile { public : virtual void transform () virtual void ability () virtual ~AbstractSmile () {} }; class SheepSmile : public AbstractSmile{ public : void transform () override { cout << "变成人兽 -- 山羊人形态..." << endl; } void ability () override { cout << "将手臂变成绵羊角的招式 -- 巨羊角" << endl; } }; class LionSmile : public AbstractSmile{ public : void transform () override { cout << "变成人兽 -- 狮子人形态..." << endl; } void ability () override { cout << "火遁· 豪火球之术..." << endl; } }; class BatSmile : public AbstractSmile{ public : void transform () override { cout << "变成人兽 -- 蝙蝠人形态..." << endl; } void ability () override { cout << "声纳引箭之万剑归宗..." << endl; } }; enum class Type :char {SHEEP, LION, BAT};class SmileFactory { public : SmileFactory () {} ~SmileFactory () {} AbstractSmile* createSmile (Type type) { AbstractSmile* ptr = nullptr ; switch (type) { case Type::SHEEP: ptr = new SheepSmile; break ; case Type::LION: ptr = new LionSmile; break ; case Type::BAT: ptr = new BatSmile; break ; default : break ; } return ptr; } }; int main () SmileFactory* factory = new SmileFactory; AbstractSmile* obj = factory->createSmile (Type::BAT); obj->transform (); obj->ability (); return 0 ; }
通过上面的代码,我们实现了一个简单工厂模式,关于里边的细节有以下几点需要说明:
由于人造恶魔果实类有继承关系, 并且实现了多态,所以父类的析构函数也应该是虚函数,这样才能够通过父类指针或引用析构子类的对象。
工厂函数createSmile(Type type)的返回值修改成了AbstractSmile*类型,这是人造恶魔果实类的基类,通过这个指针保存的是子类对象的地址,这样就实现了多态,所以在main()函数中,通过obj对象调用的实际是子类BatSmile中的函数,因此打印出的信息应该是这样的:
1 2 变成人兽 -- 蝙蝠人形态... 声纳引箭之万剑归宗...
5. 工厂模式 5.1 简单工厂模式的弊端 简单工厂模式中,有一个弊端,它违反了设计模式中的开放-封闭原则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 enum class Type :char {SHEEP, LION, BAT};class SmileFactory { public : SmileFactory () {} ~SmileFactory () {} AbstractSmile* createSmile (Type type) { AbstractSmile* ptr = nullptr ; switch (type) { case Type::SHEEP: ptr = new SheepSmile; break ; case Type::LION: ptr = new LionSmile; break ; case Type::BAT: ptr = new BatSmile; break ; default : break ; } return ptr; } };
在上面的工厂函数中需要生成三种人造恶魔果实,现在如果想要生成更多,那么就需要在工厂函数的switch语句中添加更多的case,很明显这违背了封闭原则,也就意味着需要基于开放原则来解决这个问题。
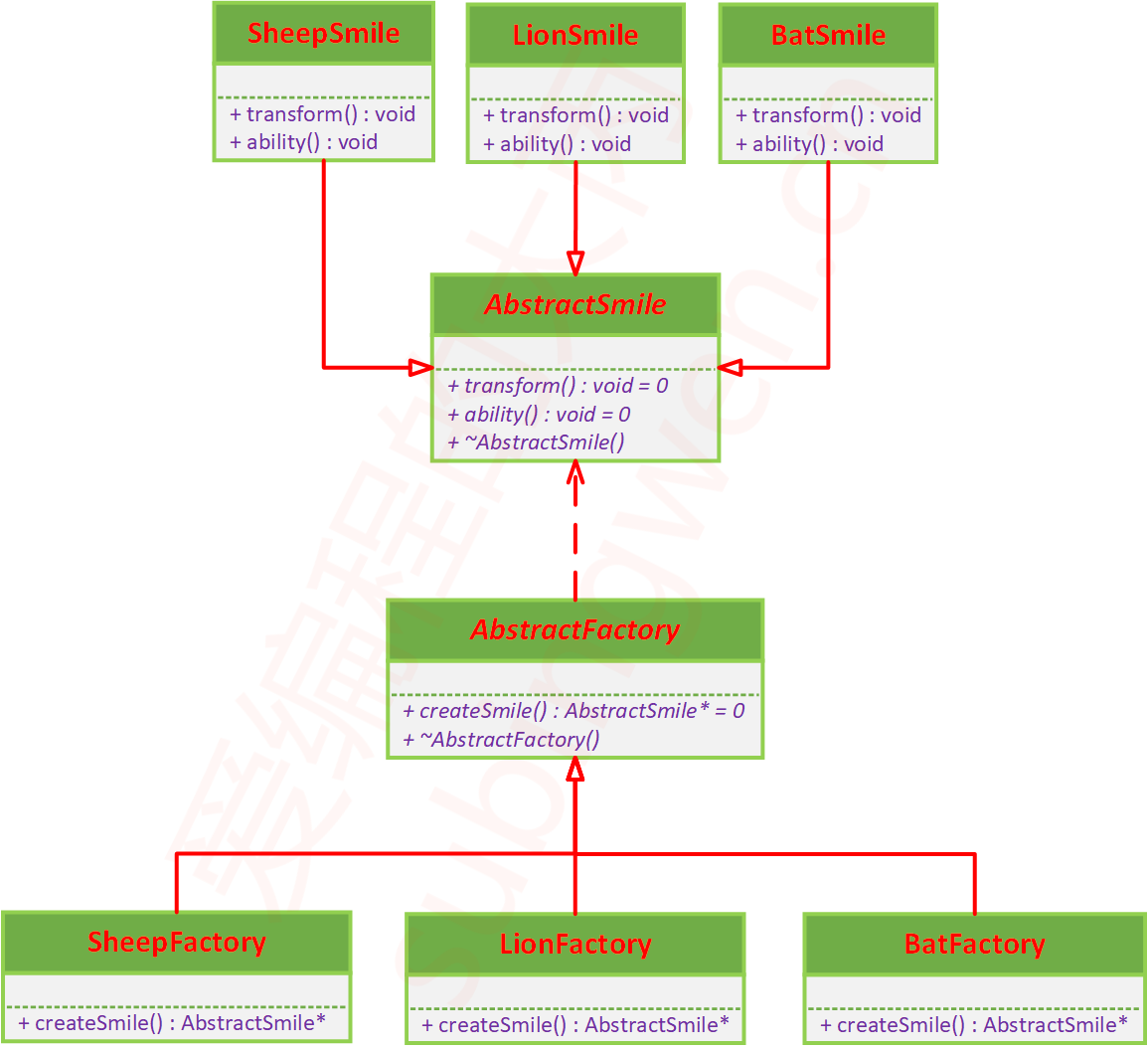
使用工厂模式可以很完美的解决上述的问题,简单工厂模式是只有一个工厂类,而工厂模式是有很多的工厂类:
5.2 工厂模式 修改一下简单工厂模式中工厂类相关的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class AbstractFactory { public : virtual AbstractSmile* createSmile () 0 ; virtual ~AbstractFactory () {} }; class SheepFactory : public AbstractFactory{ public : AbstractSmile* createSmile () override { return new SheepSmile; } ~SheepFactory () { cout << "释放 SheepFactory 类相关的内存资源" << endl; } }; class LionFactory : public AbstractFactory{ public : AbstractSmile* createSmile () override { return new LionSmile; } ~LionFactory () { cout << "释放 LionFactory 类相关的内存资源" << endl; } }; class BatFactory : public AbstractFactory{ public : AbstractSmile* createSmile () override { return new BatSmile; } ~BatFactory () { cout << "释放 BatFactory 类相关的内存资源" << endl; } };
通过示例代码可以看到,每个工厂类其实都不复杂,在每个子工厂类中也只是重写了父类的工厂方法而已,每个子工厂类生产一种恶魔果实,但是工厂函数的返回值确是恶魔果实类的基类类型,相当于是使用父类指针指向了子类对象,此处也是用到了多态。 通过这样的处理,工厂函数也就不再需要参数了。
根据简单工厂模式的代码和上面的修改就可以把工厂模式的UML类图画出来了:
完整的代码应该是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 #include <iostream> using namespace std;class AbstractSmile { public : virtual void transform () 0 ; virtual void ability () 0 ; virtual ~AbstractSmile () {} }; class SheepSmile : public AbstractSmile{ public : void transform () override { cout << "变成人兽 -- 山羊人形态..." << endl; } void ability () override { cout << "将手臂变成绵羊角的招式 -- 巨羊角" << endl; } }; class LionSmile : public AbstractSmile{ public : void transform () override { cout << "变成人兽 -- 狮子人形态..." << endl; } void ability () override { cout << "火遁· 豪火球之术..." << endl; } }; class BatSmile : public AbstractSmile{ public : void transform () override { cout << "变成人兽 -- 蝙蝠人形态..." << endl; } void ability () override { cout << "声纳引箭之万剑归宗..." << endl; } }; class AbstractFactory { public : virtual AbstractSmile* createSmile () 0 ; virtual ~AbstractFactory () {} }; class SheepFactory : public AbstractFactory{ public : AbstractSmile* createSmile () override { return new SheepSmile; } ~SheepFactory () { cout << "释放 SheepFactory 类相关的内存资源" << endl; } }; class LionFactory : public AbstractFactory{ public : AbstractSmile* createSmile () override { return new LionSmile; } ~LionFactory () { cout << "释放 LionFactory 类相关的内存资源" << endl; } }; class BatFactory : public AbstractFactory{ public : AbstractSmile* createSmile () override { return new BatSmile; } ~BatFactory () { cout << "释放 BatFactory 类相关的内存资源" << endl; } }; int main () AbstractFactory* factory = new BatFactory; AbstractSmile* obj = factory->createSmile (); obj->transform (); obj->ability (); return 0 ; }
在main()函数中的这句代码是实例化了一个生成蝙蝠恶魔果实的工厂对象:
1 AbstractFactory* factory = new BatFactory;
在真实的项目场景中,要生成什么类型的恶魔果实其实是通过客户端的操作界面控制的,它对应的可能是一个按钮或者是一个选择列表,用户做出了选择,程序就可以根据该需求去创建对应的工厂对象,最终将选择的恶魔果实生产出来。
在上面的例子中,不论是恶魔果实的基类,还是工厂类的基类,它们的虚函数可以是纯虚函数,也可以是非纯虚函数。这样的基类在设计模式中就可以称之为抽象类(此处的抽象类和C++中对抽象类的定义有一点出入)。
6. 抽象工厂模式 6.1 船支设计 提供了不同型号的海贼船,一共是三个级别,如下表:
基础型
标准型
旗舰型
船体
木头
钢铁
合成金属
动力
手动
内燃机
核能
武器
枪
速射炮
激光
根据这个表,在造船的时候需要根据不同的型号选择相应的零部件,在设计程序的时候还需要保证遵循开放-封闭原则,即添加了新型号之后不需要修改原有代码,而是添加新的代码。
6.1.1 船体 因为要建造的这艘船是由多个部件组成的并且每个部件还有不同的品级可供选择,先说船体,关于船体材料的这个属性是可变的,所以还需要给它提供一个抽象类,这样在这个抽象类的子类中就可以更换不同的船体材料了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class ShipBody { public : virtual string getShipBody () 0 ; virtual ~ShipBody () {} }; class WoodBody : public ShipBody{ public : string getShipBody () override { return string ("用<木材>制作轮船船体..." ); } }; class IronBody : public ShipBody{ public : string getShipBody () override { return string ("用<钢铁>制作轮船船体..." ); } }; class MetalBody : public ShipBody{ public : string getShipBody () override { return string ("用<合金>制作轮船船体..." ); } };
这样,只要添加了新的造船材料,就给它添加一个对应的子类(父类是 ShipBody),在这个子类重写父类的虚函数getShipBody(),用这种材料把船体造出来就行了。
6.1.2 动力和武器 知道了如何处理船体部分,那么动力和武器部分的处理思路也是一样的:
可以给船提供不同的动力系统,因此这个属性是可变的,所以需要提供一个抽象类
可以给船提供不同的武器系统,因此这个属性也是可变的,所以也需要提供一个抽象类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class Engine { public : virtual string getEngine () 0 ; virtual ~Engine () {} }; class Human : public Engine{ public : string getEngine () override { return string ("使用<人力驱动>..." ); } }; class Diesel : public Engine{ public : string getEngine () override { return string ("使用<内燃机驱动>..." ); } }; class Nuclear : public Engine{ public : string getEngine () override { return string ("使用<核能驱动>..." ); } }; class Weapon { public : virtual string getWeapon () 0 ; virtual ~Weapon () {} }; class Gun : public Weapon{ public : string getWeapon () override { return string ("配备的武器是<枪>" ); } }; class Cannon : public Weapon{ public : string getWeapon () override { return string ("配备的武器是<自动机关炮>" ); } }; class Laser : public Weapon{ public : string getWeapon () override { return string ("配备的武器是<激光>" ); } };
不论是动力还是武器系统都是需要提供一个抽象类,这样它们的子类就可以基于这个抽象基类进行专门定制,如果要对它们进行拓展也只需添加新的类,不需要修改原有代码。
6.1.3 一艘船 如果有了以上的零件,只需要在工厂中将它们装配到一起,这样就得到了一艘船,这是一艘什么型号的船取决于使用的是什么零件,所以只需要让这艘船对应一个类就可以了,这个类的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Ship { public : Ship (ShipBody* body, Weapon* weapon, Engine* engine) : m_body (body), m_weapon (weapon), m_engine (engine) { } string getProperty () { string info = m_body->getShipBody () + m_weapon->getWeapon () + m_engine->getEngine (); return info; } ~Ship () { delete m_body; delete m_engine; delete m_weapon; } private : ShipBody* m_body = nullptr ; Weapon* m_weapon = nullptr ; Engine* m_engine = nullptr ; };
这艘船使用的零件是通过构造函数参数传递进来的,并在类的内部对这些零件对象进行了保存,这样在释放船这个对象的时候就可以将相应的零件对象一并析构了。
另外,在Ship这个类中保存零件对象的时候使用的是它们的父类指针,这样就可以实现多态了。
6.2 准备生产 万事俱备,只剩建厂了。造船厂要生产三种型号的船,那么也就是至少需要三条生产线,所以对应的工厂类也就不止一个,处理思路还是一样的,提供一个抽象的基类,然后在它的子类中完成各种型号的船的组装,每个子类对应的就是一条生产线。
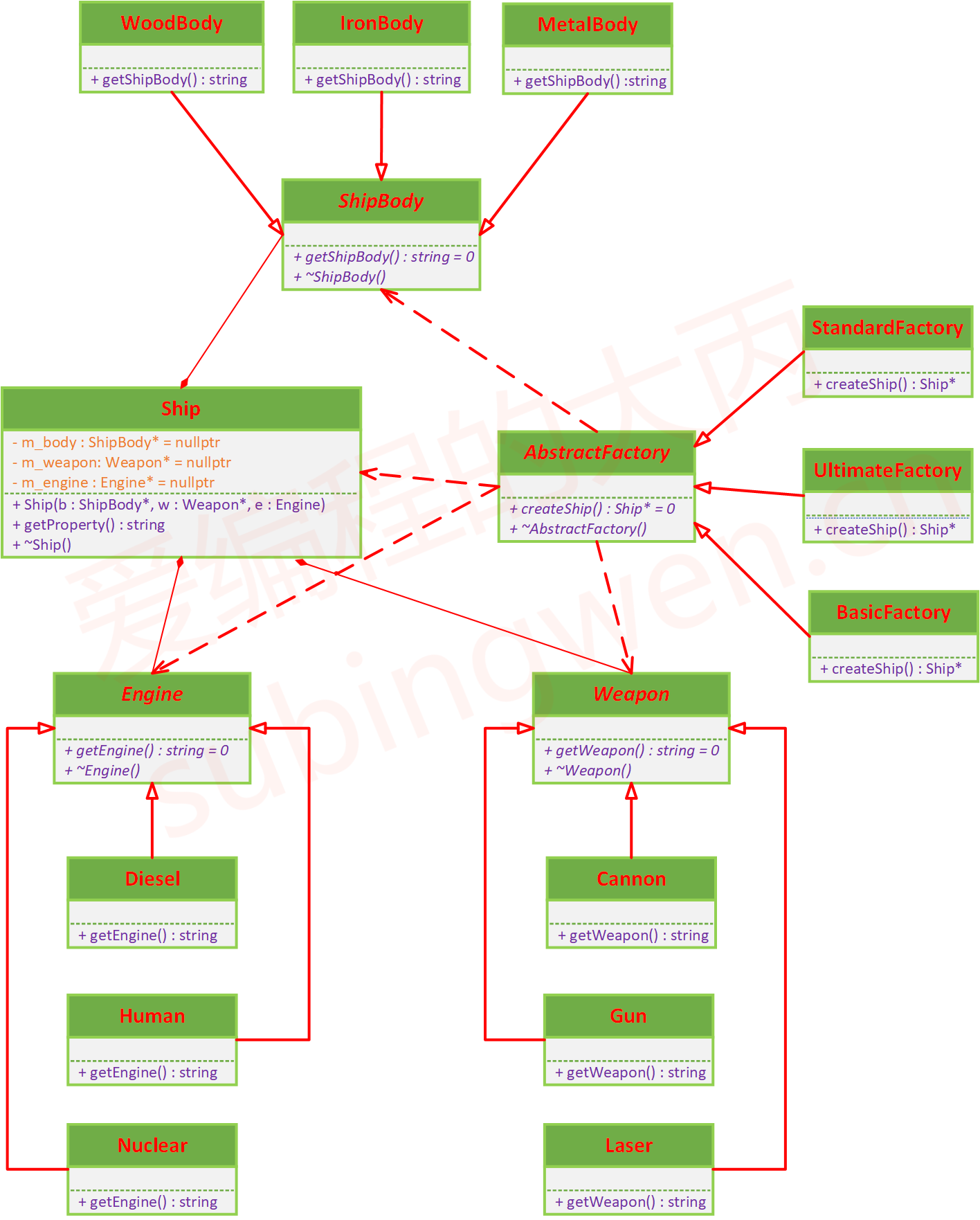
6.2.1 设计图纸 现在,关于抽象工厂模式的逻辑应该是比较清晰了,下面来看一下这个模式对应的UML类图:
在这个图中有四个抽象类,分别是:
ShipBody 类:船体的抽象类Weapon 类:武器的抽象类Engine 类:动力系统抽象类AbstractFactory 类:抽象工厂类
在子工厂类中生产不同型号的战船
和ShipBody 、Weapon、Engine有依赖关系,在工厂函数中创建了它们的实例对象
和Ship 类有依赖关系,在工厂函数中创建了它的实例对象
关于Ship类它可以和ShipBody 、Weapon、Engine可以是聚合关系,也可以是组合关系:
组合关系:析构Ship类对象的时候,也释放了ShipBody 、Weapon、Engine对象
聚合关系:析构Ship类对象的时候,没有释放ShipBody 、Weapon、Engine对象
在上面的Ship类的析构函数中做了释放操作,因此在UML中将它们之间描述为了组合关系。
在使用抽象工厂模式来处理实际问题的时候,由于实际需求不一样,我们画出的UML类图中有些类和类之间的关系可能也会有所不同,所以上图只适用于当前的业务场景,在处理其他需求的时候还需要具体问题具体分析。
6.2.2 生产 给上面的程序再添加相应的工厂类,就可以生产出我们需要的型号的船只了,示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 #include <iostream> #include <string> using namespace std;class ShipBody { public : virtual string getShipBody () 0 ; virtual ~ShipBody () {} }; class WoodBody : public ShipBody{ public : string getShipBody () override { return string ("用<木材>制作轮船船体..." ); } }; class IronBody : public ShipBody{ public : string getShipBody () override { return string ("用<钢铁>制作轮船船体..." ); } }; class MetalBody : public ShipBody{ public : string getShipBody () override { return string ("用<合金>制作轮船船体..." ); } }; class Weapon { public : virtual string getWeapon () 0 ; virtual ~Weapon () {} }; class Gun : public Weapon{ public : string getWeapon () override { return string ("配备的武器是<枪>..." ); } }; class Cannon : public Weapon{ public : string getWeapon () override { return string ("配备的武器是<自动机关炮>..." ); } }; class Laser : public Weapon{ public : string getWeapon () override { return string ("配备的武器是<激光>..." ); } }; class Engine { public : virtual string getEngine () 0 ; virtual ~Engine () {} }; class Human : public Engine{ public : string getEngine () override { return string ("使用<人力驱动>..." ); } }; class Diesel : public Engine{ public : string getEngine () override { return string ("使用<内燃机驱动>..." ); } }; class Nuclear : public Engine{ public : string getEngine () override { return string ("使用<核能驱动>..." ); } }; class Ship { public : Ship (ShipBody* body, Weapon* weapon, Engine* engine) : m_body (body), m_weapon (weapon), m_engine (engine) { } string getProperty () { string info = m_body->getShipBody () + m_weapon->getWeapon () + m_engine->getEngine (); return info; } ~Ship () { delete m_body; delete m_engine; delete m_weapon; } private : ShipBody* m_body = nullptr ; Weapon* m_weapon = nullptr ; Engine* m_engine = nullptr ; }; class AbstractFactory { public : virtual Ship* createShip () 0 ; virtual ~AbstractFactory () {} }; class BasicFactory : public AbstractFactory{ public : Ship* createShip () override { Ship* ship = new Ship (new WoodBody, new Gun, new Human); cout << "<基础型>战船生产完毕, 可以下水啦..." << endl; return ship; } }; class StandardFactory : public AbstractFactory{ public : Ship* createShip () override { Ship* ship = new Ship (new IronBody, new Cannon, new Diesel); cout << "<标准型>战船生产完毕, 可以下水啦..." << endl; return ship; } }; class UltimateFactory : public AbstractFactory{ public : Ship* createShip () override { Ship* ship = new Ship (new MetalBody, new Laser, new Nuclear); cout << "<旗舰型>战船生产完毕, 可以下水啦..." << endl; return ship; } }; int main () AbstractFactory* factroy = new StandardFactory; Ship* ship = factroy->createShip (); cout << ship->getProperty (); delete ship; delete factroy; return 0 ; }
在main()函数中,要通过工厂类的工厂函数生产什么型号的战船,和用户的需求息息相关,所以这个选择也是用户通过客户端的操作界面做出的,在这个例子中,关于客户端的界面操作就直接忽略了。
抽象工厂模式适用于比较复杂的多变的业务场景,总体上就是给一系列功能相同但是属性会发生变化的组件(如:船体材料、武器系统、动力系统)添加一个抽象类,这样就可以非常方便地进行后续的拓展,再搭配工厂类就可以创建出我们需要的对象了。
关于简单工厂模式、工厂模式和抽象工厂模式的区别可以做如下总结:
简单工厂模式不能遵守开放-封闭原则,工厂和抽象工厂模式可以
简单工厂模式只有一个工厂类,工厂和抽象工厂有多个工厂类
工厂模式创建的产品对象相对简单,抽象工厂模式创建的产品对象相对复杂
工厂模式创建的对象对应的类不需要提供抽象类【这产品类组件中没有可变因素】 抽象工厂模式创建的对象对应的类有抽象的基类【这个产品类组件中有可变因素】
7. 生成器(建造者模式) 化繁为简,逐个击破。也就是分步骤创建复杂的对象,并且允许使用相同的代码生成不同类型和形式的对象,这种模式叫做生成器模式(也叫建造者模式)
7.1 模式特征 7.1.1 生成器 生成器模式建议将造船工序的代码从产品类中抽取出来, 并将其放在一个名为生成器的独立类中。
在这个生成器类中有一系列的构建步骤,每次造船的时候,只需从中选择需要的步骤并调用就可以得到满足需求的实例对象。
假设我们要通过上面的生成器建造很多不同规格、型号的海贼船,那么就需要创建多个生成器,但是有一点是不变的:生成器内部的构建步骤不变。
基础型
标准型
旗舰型
船体
有
有
有
动力
有
有
有
武器
无
有
有
内室
毛坯
毛坯
精装
比如,我想建造两种型号的海贼船:桑尼号和梅利号,并且按照上面的三个规格,每种造一艘,此时就需要两个生成器:桑尼号生成器和梅利号生成器,并且这两个生成器还需要对应一个父类,父类生成器中的建造函数应该设置为虚函数。
7.1.2 主管 可以进一步将用于创建产品的一系列生成器步骤调用抽取成为单独的主管类。主管类可定义创建步骤的执行顺序, 而生成器则提供这些步骤的实现。
严格来说, 程序中并不一定需要主管类。 客户端代码可直接以特定顺序调用创建步骤。 不过, 主管类中非常适合放入各种例行构造流程, 以便在程序中反复使用。
此外, 对于客户端代码来说, 主管类完全隐藏了产品构造细节。 客户端只需要将一个生成器与主管类关联, 然后使用主管类来构造产品, 就能从生成器处获得构造结果了。
7.2 建造 7.2.1 船模型 现在我们开始着手把 桑尼号 和 梅利号使用生成器模式键造出来。
一共需要三个生成器类,一共父类,两个子类
父类可以是一个抽象类,提供的建造函数都是虚函数
在两个生成器子类中,使用建造函数分别将 桑尼号 和 梅利号 各个零部件造出来。
如果我们仔细分析,发现还需要解决另外一个问题,通过生成器得到了海贼船的各个零部件,这些零部件必须有一个载体,那就是海贼船对象。因此,还需要提供一个或多个海贼船类。
因为 桑尼号 和 梅利号 这两艘的差别非常大,所以我们定义两个海贼船类,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class SunnyShip { public : void addParts (string name) { m_parts.push_back (name); } void showParts () { for (const auto & item : m_parts) { cout << item << " " ; } cout << endl; } private : vector<string> m_parts; }; class MerryShip { public : void assemble (string name, string parts) { m_patrs.insert (make_pair (name, parts)); } void showParts () { for (const auto & item : m_patrs) { cout << item.first << ": " << item.second << " " ; } cout << endl; } private : map<string, string> m_patrs; };
在上面的两个类中,通过一个字符串来代表某个零部件,为了使这两个类有区别SunnyShip 类中使用vector 容器存储数据,MerryShip 类中使用map 容器存储数据。
7.2.2 船生成器 虽然有海贼船类,但是这两个海贼船类并不造船,每艘船的零部件都是由他们对应的生成器类构建完成的,下面是生成器类的代码:
抽象生成器 1 2 3 4 5 6 7 8 9 10 11 class ShipBuilder { public : virtual void reset () 0 ; virtual void buildBody () 0 ; virtual void buildWeapon () 0 ; virtual void buildEngine () 0 ; virtual void buildInterior () 0 ; virtual ~ShipBuilder () {} };
在这个抽象类中定义了建造海贼船所有零部件的方法,在这个类的子类中需要重写这些虚函数,分别完成桑尼号 和 梅利号零件的建造。
桑尼号生成器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class SunnyBuilder : public ShipBuilder{ public : SunnyBuilder () { reset (); } ~SunnyBuilder () { if (m_sunny != nullptr ) { delete m_sunny; } } void reset () override { m_sunny = new SunnyShip; } void buildBody () override { m_sunny->addParts ("神树亚当的树干" ); } void buildWeapon () override { m_sunny->addParts ("狮吼炮" ); } void buildEngine () override { m_sunny->addParts ("可乐驱动" ); } void buildInterior () override { m_sunny->addParts ("豪华内室精装" ); } SunnyShip* getSunny () { SunnyShip* ship = m_sunny; m_sunny = nullptr ; return ship; } private : SunnyShip* m_sunny = nullptr ; };
在这个生成器类中只要调用build 方法,对应的零件就会被加载到SunnyShip 类的对象 m_sunny 中,当船被造好之后就可以通过SunnyShip* getSunny()方法得到桑尼号的实例对象,当这个对象地址被外部指针接管之后,当前生成器类就不会再维护其内存的释放了。如果想通过生成器对象建造第二艘桑尼号就可以调用这个类的reset()方法,这样就得到了一个新的桑尼号对象,之后再调用相应的建造函数,这个对象就被初始化了。
梅利号生成器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class MerryBuilder : public ShipBuilder{ public : MerryBuilder () { reset (); } ~MerryBuilder () { if (m_merry != nullptr ) { delete m_merry; } } void reset () override { m_merry = new MerryShip; } void buildBody () override { m_merry->assemble ("船体" , "优质木材" ); } void buildWeapon () override { m_merry->assemble ("武器" , "四门大炮" ); } void buildEngine () override { m_merry->assemble ("动力" , "蒸汽机" ); } void buildInterior () override { m_merry->assemble ("内室" , "精装" ); } MerryShip* getMerry () { MerryShip* ship = m_merry; m_merry = nullptr ; return ship; } private : MerryShip* m_merry = nullptr ; };
梅利号的生成器和桑尼号的生成器内部做的事情是一样的,在此就不过多赘述了。
7.2.3 主管类 如果想要隐藏造船细节,就可以添加一个主管类,这个主管类就相当于一个包工头,脏活累活他都干了,我们看到的就是一个结果。
根据需求,桑尼号和梅利号分别有三个规格,简约型、标准型、豪华型,根据不同的规格,有选择的调用生成器中不同的建造函数,就可以得到最终的成品了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Director { public : void setBuilder (ShipBuilder* builder) { m_builder = builder; } void builderSimpleShip () { m_builder->buildBody (); m_builder->buildEngine (); } void builderStandardShip () { builderSimpleShip (); m_builder->buildWeapon (); } void builderRegalShip () { builderStandardShip (); m_builder->buildInterior (); } private : ShipBuilder* m_builder = nullptr ; };
在使用主管类的时候,需要通过setBuilder(ShipBuilder* builder)给它的对象传递一个生成器对象,形参是父类指针,实参应该是子类对象,这样做的目的是为了实现多态,并且在这个地方这个函数是一个传入传出参数。
7.3 验收 最后测试一个桑尼号和梅利号分别对应的三种规格的船能否被建造出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 void builderSunny () Director* director = new Director; SunnyBuilder* builder = new SunnyBuilder; director->setBuilder (builder); director->builderSimpleShip (); SunnyShip* sunny = builder->getSunny (); sunny->showParts (); delete sunny; builder->reset (); director->setBuilder (builder); director->builderStandardShip (); sunny = builder->getSunny (); sunny->showParts (); delete sunny; builder->reset (); director->setBuilder (builder); director->builderRegalShip (); sunny = builder->getSunny (); sunny->showParts (); delete sunny; delete builder; delete director; } void builderMerry () Director* director = new Director; MerryBuilder* builder = new MerryBuilder; director->setBuilder (builder); director->builderSimpleShip (); MerryShip* merry = builder->getMerry (); merry->showParts (); delete merry; builder->reset (); director->setBuilder (builder); director->builderStandardShip (); merry = builder->getMerry (); merry->showParts (); delete merry; builder->reset (); director->setBuilder (builder); director->builderRegalShip (); merry = builder->getMerry (); merry->showParts (); delete merry; delete builder; delete director; } int main () builderSunny (); cout << "=====================================" << endl; builderMerry (); }
程序输出:
1 2 3 4 5 6 7 神树亚当的树干 可乐驱动 神树亚当的树干 可乐驱动 狮吼炮 神树亚当的树干 可乐驱动 狮吼炮 豪华内室精装 ===================================== 船体: 优质木材 动力: 蒸汽机 船体: 优质木材 动力: 蒸汽机 武器: 四门大炮 船体: 优质木材 动力: 蒸汽机 内室: 精装 武器: 四门大炮
可以看到,输出结果是没问题的,使用生成器模式造船成功!
7.4 UML 最后根据上面的代码把UML类图画一下(在学习设计模式的时候只能最后出图,在做项目的时候应该是先画UML类图,再写程序)。
通过编写的代码可得知Director 类 和 ShipBuilder 类之间有两种关系依赖和关联,但在描述这二者的关系的时候只能画一条线,一般会选择最紧密的那个关系,在此处就是关联关系。
在这个图中,没有把使用这用这些类的客户端画出来,这个客户端对应的是上面程序中的main()函数中调用的测试代码,在真实场景中对应的应该是一个客户端操作界面,由用户做出选择,从而在程序中根据选择建造不同型号,不同规格的船。
8. 原型模式
克隆是一种最直接、最快捷的创建新对象的方式,它不仅隐藏了创建新对象的诸多细节,还保留了源对象的属性信息,保证了这两个对象能够一模一样。即原型模式
在C++中只要定义一个类,这个类就默认自带六大函数,其中一个就是拷贝构造函数,这个函数的作用就是通过一个已有对象克隆出一个新的对象。
我们可能想要通父类指针或引用把指向的子类对象克隆出来
通过这个描述,就可以从里面挖掘出一个重要的信息:克隆可能会在父类和子类之间进行,并且可能是动态的,很明显通过父类的拷贝构造函数无法实现对子类对象的拷贝,其实这就是一个多态,我们需要给父类提供一个克隆函数并且是一个虚函数。
对应UML类图
根据上面的UML类图,我们就可以把对应的代码写出了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> using namespace std;class GermaSoldier { public : virtual GermaSoldier* clone () 0 ; virtual string whoAmI () 0 ; virtual ~GermaSoldier () {} }; class Soldier66 : public GermaSoldier{ public : GermaSoldier* clone () override { return new Soldier66 (*this ); } string whoAmI () override { return string ("我是杰尔马66的超级士兵!!!" ); } }; class Soldier67 : public GermaSoldier{ public : GermaSoldier* clone () { return new Soldier67 (*this ); } string whoAmI () override { return string ("我是杰尔马67的超级士兵!!!" ); } }; int main () GermaSoldier* obj = new Soldier66; GermaSoldier* soldier = obj->clone (); cout << soldier->whoAmI () << endl; delete soldier; delete obj; obj = new Soldier67; soldier = obj->clone (); cout << soldier->whoAmI () << endl; delete soldier; delete obj; }
代码中的main()函数对应的就是UML类图中的客户端角色。
第41行通过父类指针克隆了子类Soldier66的对象
第47行通过父类指针克隆了子类Soldier67的对象
在这两个士兵子类的clone()函数体内部是通过当前子类的拷贝构造函数复制出了一个新的子类对象。
程序执行的结果如下:
1 2 我是杰尔马66 的超级士兵!!! 我是杰尔马67 的超级士兵!!!
通过输出的结果可以看到通过父类指针克隆子类的对象成功了