1. 文件描述符 1.1 虚拟地址空间 虚拟地址空间是一个非常抽象的概念,先根据字面意思进行解释:
它可以用来加载程序数据(数据可能被加载到物理内存上,空间不够就加载到虚拟内存中)
虚拟地址空间的大小也由操作系统决定,32位的操作系统虚拟地址空间的大小为 2^32^ 字节,也就是4G,64位的操作系统虚拟地址空间大小为2^64^ 字节,也就是16777216T。
当我们运行磁盘上一个可执行程序, 就会得到一个进程,内核会给每一个运行的进程创建一块属于自己的虚拟地址空间,并将应用程序数据装载到虚拟地址空间对应的地址上。
进程在运行过程中,程序内部所有的指令都是通过CPU处理完成的,CPU只进行数据运算并不具备数据存储的能力,其处理的数据都加载自物理内存
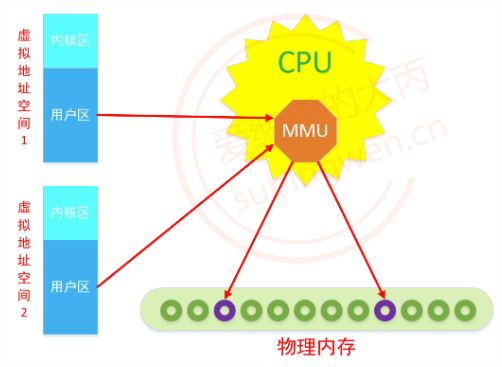
1.1.1 存在的意义 为什么操作系统不直接将数据加载到物理内存中而是将数据加载到虚拟地址空间中,在通过CPU的MMU映射到物理内存中呢?
看一下如果直接将数据加载到物理内存会发生什么事情:
假设计算机的物理内存大小为1G, 进程A需要100M内存因此直接在物理内存上从0地址开始分配100M, 进程B启动需要250M内存,因此继续在物理内存上为其分配250M内存
使用这种方式分配内存会有如下几个问题:
每个进程的地址不隔离,有安全风险。
由于程序都是直接访问物理内存,所以恶意程序可以通过内存寻址随意修改别的进程对应的内存数据,以达到破坏的目的。虽然有些时候是非恶意的,但是有些存在 bug 的程序可能不小心修改了其它程序的内存数据,就会导致其它程序的运行出现异常。
内存效率低。
如果直接使用物理内存的话,一个进程对应的内存块就是作为一个整体操作的
进程中数据的地址不确定,每次都会发生变化。
由于物理内存的使用情况一直在动态的变化,我们无法确定内存现在使用到哪里了,如果直接将程序数据加载到物理内存,内存中每次存储数据的起始地址都是不一样的,这样数据的加载都需要使用相对地址,加载效率低(静态库是使用绝对地址加载的)。
有了虚拟地址空间之后就可以完美的解决上边提到的所有问题了,虚拟地址空间就是一个中间层,相当于在程序和物理内存之间设置了一个屏障,将二者隔离开来。
1.1.2 分区 从操作系统层级上看,虚拟地址空间主要分为两个部分内核区和用户区。
内核区 :
内核空间为内核保留,不允许应用程序读写该区域的内容或直接调用内核代码定义的函数。
内核总是驻留在内存中,是操作系统的一部分。
系统中所有进程对应的虚拟地址空间的内核区都会映射到同一块物理内存上(系统内核只有一个)。
用户区 :存储用户程序运行中用到的各种数据。
先看进程对应的虚拟地址空间的各个分区,再来详细介绍用户区的组成(以32位系统的虚拟地址空间为例)。
每个进程的虚拟地址空间都是从0地址开始的,我们在程序中打印的变量地址也其在虚拟地址空间中的地址,程序是无法直接访问物理内存的。
虚拟地址空间中用户区地址范围是 0~3G,里边分为多个区块:
保留区: 位于虚拟地址空间的最底部,未赋予物理地址。任何对它的引用都是非法的,程序中的空指针(NULL)指向的就是这块内存地址。.text段: 代码段也称正文段或文本段,通常用于存放程序的执行代码(即CPU执行的机器指令),代码段一般情况下是只读的,这是对执行代码的一种保护机制。.data段: 数据段通常用于存放程序中已初始化且初值不为0的全局变量和静态变量。数据段属于静态内存分配(静态存储区),可读可写。.bss段: 未初始化以及初始为0的全局变量和静态变量,操作系统会将这些未初始化变量初始化为0堆(heap):用于存放进程运行时动态分配的内存。
堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。
堆向高地址扩展(即“向上生长”),是不连续的内存区域。
内存映射区(mmap):作为内存映射区加载磁盘文件,或者加载程序运作过程中需要调用的动态库。栈(stack): 存储函数内部声明的非静态局部变量,函数参数,函数返回地址等信息,栈内存由编译器自动分配释放。栈和堆相反地址“向下生长”,分配的内存是连续的。命令行参数:存储进程执行的时候传递给main()函数的参数,argc,argv[]环境变量: 存储和进程相关的环境变量, 比如: 工作路径, 进程所有者等信息
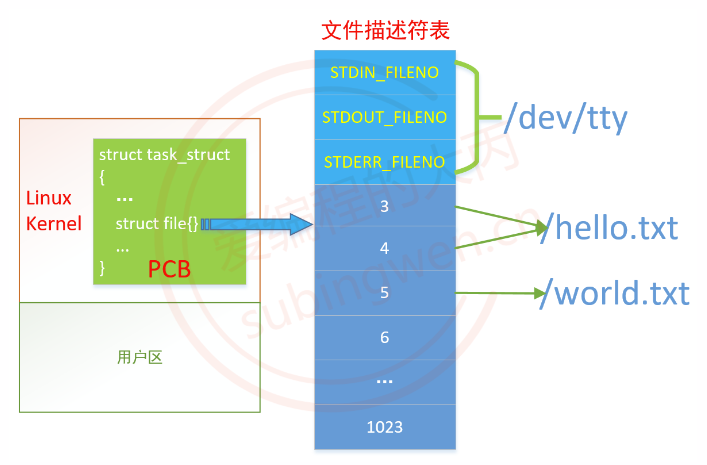
1.2 文件描述符 1.2.1 文件描述符 在Linux操作系统中的一切都被抽象为文件,那么一个打开的文件是如何与应用程序进行对应呢?文件描述符(file descriptor,简称fd),当在进程中打开一个现有文件或者创建一个新文件时,内核向该进程返回一个文件描述符,用于对应这个打开/新建的文件。
在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
在Linux系统中一切皆文件,系统中一切都被抽象成了文件。对这些文件的读写都需要通过文件描述符来完成。FILE*在Linux中也需要通过文件描述符的辅助才能完成读写操作。FILE其实是一个结构体,其内部有一个成员就是文件描述符(下面结构体的第25行)。
FILE结构体在Linux头文件中的定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 struct _IO_FILE { int _flags; #define _IO_file_flags _flags char * _IO_read_ptr; char * _IO_read_end; char * _IO_read_base; char * _IO_write_base; char * _IO_write_ptr; char * _IO_write_end; char * _IO_buf_base; char * _IO_buf_end; char *_IO_save_base; char *_IO_backup_base; char *_IO_save_end; struct _IO_marker *_markers ; struct _IO_FILE *_chain ; int _fileno; #if 0 int _blksize; #else int _flags2; #endif _IO_off_t _old_offset; #define __HAVE_COLUMN unsigned short _cur_column; signed char _vtable_offset; char _shortbuf[1 ]; _IO_lock_t *_lock; #ifdef _IO_USE_OLD_IO_FILE }; typedef struct _IO_FILE FILE ;
1.2.2 文件描述符表 前面讲到启动一个进程就会得到一个对应的虚拟地址空间,这个虚拟地址空间分为两大部分,在内核区有专门用于进程管理的模块。Linux的进程控制块PCB(process control block)本质是一个叫做task_struct的结构体,里边包括管理进程所需的各种信息,其中有一个结构体叫做file ,我们将它叫做文件描述符表,里边有一个整形索引表,用于存储文件描述符。
内核为每一个进程维护了一个文件描述符表,索引表中的值都是从0开始的,所以在不同的进程中你会看到相同的文件描述符,但是它们指向的不一定是同一个磁盘文件。
Linux中用户操作的每个终端都被视作一个设备文件, 当前操作的终端文件可以使用 /dev/tty表示。
每一个进程对应的文件描述符表能够存储的打开的文件数是有限制的, 默认为1024个,这个默认值是可以修改的,支持打开的最大文件数据取决于操作系统的硬件配置。
默认分配的文件描述符
STDIN_FILENO:标准输入,可以通过这个文件描述符将数据输入到终端文件中,宏值为0。STDOUT_FILENO:标准输出,可以通过这个文件描述符将数据通过终端输出出来,宏值为1。STDERR_FILENO:标准错误,可以通过这个文件描述符将错误信息通过终端输出出来,宏值为2。
这三个默认分配的文件描述符是可以通过close()函数关闭掉,但是关闭之后当前进程也就不能和当前终端进行输入或者输出的信息交互了。
给新打开的文件分配文件描述符
因为进程启动之后,文件描述符表中的0,1,2就被分配出去了,因此从3开始分配
在进程中每打开一个文件,就会给这个文件分配一个新的文件描述符,比如:
通过open()函数打开 /hello.txt,文件描述符 3 被分配给了这个文件,保持这个打开状态,再次通过open()函数打开 /hello.txt,文件描述符 4 被分配给了这个文件,也就是说一个进程中不同的文件描述符打开的磁盘文件可能是同一个。
通过open()函数打开 /hello.txt ,文件描述符 3 被分配给了这个文件,将打开的文件关闭,此时文件描述符3就被释放了。再次通过open()函数打开 /hello.txt,文件描述符 3 被分配给了这个文件,也就是说打开的新文件会关联文件描述符表中最小的没有被占用的文件描述符。
总结:
每个进程对应的文件描述符表默认支持打开的最大文件数为 1024,可以修改
每个进程的文件描述符表中都已经默认分配了三个文件描述符,对应的都是当前终端文件(/dev/tty)
每打开新的文件,内核会从进程的文件描述符表中找到一个空闲的没有别占用的文件描述符与其进行关联
文件描述符表中不同的文件描述符可以对应同一个磁盘文件
每个进程文件描述符表中的文件描述符值是唯一的,不会重复
2. Linux系统文件IO 每个系统都有自己的专属函数,我们习惯称其为系统函数。系统函数并不是内核函数,因为内核函数是不允许用户使用的,系统函数就充当了二者之间的桥梁,这样用户就可以间接的完成某些内核操作了。
在前面介绍了文件描述符,在Linux系统中必须要使用系统提供的IO函数才能基于这些文件描述符完成对相关文件的读写操作。这些Linux系统IO函数和标准C库的IO函数使用方法类似,函数名称也类似
2.1 open/close 2.1.1 函数原型
通过open函数我们即可打开一个磁盘文件,如果磁盘文件不存在还可以创建一个新的的文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int open (const char *pathname, int flags) ;int open (const char *pathname, int flags, mode_t mode) ;
参数介绍:
假设 mode 参数的值为 0777, 通过计算得到的文件权限为 0775
1 2 3 4 5 6 7 8 9 10 111111111 & 111111101 ------------------ 111111101 二进制 ------------------ mod=0775 八进制
返回值:
成功: 返回内核分配的文件描述符, 这个值被记录在内核的文件描述符表中,这是一个大于0的整数
失败: -1
2.1.2 close函数原型
通过open函数可以让内核给文件分配一个文件描述符, 如果需要释放这个文件描述符就需要关闭文件。对应的这个系统函数叫做 close
1 2 3 #include <unistd.h> int close (int fd) ;
函数参数: fd 是文件描述符, 是open() 函数的返回值
函数返回值: 函数调用成功返回值 0, 调用失败返回 -1
2.1.3 打开已存在文件
我们可以使用open()函数打开一个本地已经存在的文件, 假设我们想要读写这个文件, 操作代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("abc.txt" , O_RDWR); if (fd == -1 ) { printf ("打开文件失败\n" ); } else { printf ("fd: %d\n" , fd); } close(fd); return 0 ; }
编译并执行程序
1 2 3 $ gcc open.c $ ./a.out fd: 3
2.1.4 创建新文件
如果要创建一个新的文件,还是使用 open 函数,只不过需要添加 O_CREAT 属性, 并且给新文件指定操作权限。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./new.txt" , O_CREAT|O_RDWR, 0664 ); if (fd == -1 ) { printf ("打开文件失败\n" ); } else { printf ("创建新文件成功, fd: %d\n" , fd); } close(fd); return 0 ; }
1 2 3 $ gcc open1.c $ ./a.out 创建新文件成功, fd: 3
假设在创建新文件的时候, 给 open 指定第三个参数指定新文件的操作权限, 文件也是会被创建出来的, 只不过新的文件的权限可能会有点奇怪, 这个权限会随机分配而且还会出现一些特殊的权限位, 如下:
1 2 $ $ ll new.txt -r-x--s--T 1 robin robin 0 Jan 30 16:17 new.txt*
2.1.5 文件状态判断
在创建新文件的时候我们还可以通过 O_EXCL进行文件的检测, 具体处理方式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./new.txt" , O_CREAT|O_EXCL|O_RDWR); if (fd == -1 ) { printf ("创建文件失败, 已经存在了, fd: %d\n" , fd); } else { printf ("创建新文件成功, fd: %d\n" , fd); } close(fd); return 0 ; }
编译并执行程序:
1 2 3 $ gcc open1.c $ ./a.out 创建文件失败, 已经存在了, fd: -1
2.2 read/write 2.2.1 read
read 函数用于读取文件内部数据,在通过 open 打开文件的时候需要指定读权限
1 2 3 #include <unistd.h> ssize_t read (int fd, void *buf, size_t count) ;
参数:
fd: 文件描述符, open() 函数的返回值, 通过这个参数定位打开的磁盘文件buf: 是一个传出参数, 指向一块有效的内存, 用于存储从文件中读出的数据
传出参数: 类似于返回值, 将变量地址传递给函数, 函数调用完毕, 地址中就有数据了
count: buf指针指向的内存的大小, 指定可以存储的最大字节数
返回值:
大于0: 从文件中读出的字节数,读文件成功
等于0: 代表文件读完了,读文件成功
-1: 读文件失败了
2.2.2 write
write 函数用于将数据写入到文件内部,在通过 open 打开文件的时候需要指定写权限
1 2 3 #include <unistd.h> ssize_t write (int fd, const void *buf, size_t count) ;
参数:
fd: 文件描述符, open() 函数的返回值, 通过这个参数定位打开的磁盘文件buf: 指向一块有效的内存地址, 里边有要写入到磁盘文件中的数据count: 要往磁盘文件中写入的字节数, 一般情况下是buf字符串的长度, strlen(buf)
返回值:
大于0: 成功写入到磁盘文件中的字节数
-1: 写文件失败了
2.2.3 文件拷贝
假设有一个比较大的磁盘文件, 打开这个文件得到文件描述符fd1,然后在创建一个新的磁盘文件得到文件描述符fd2, 在程序中通过 fd1将文件内容读出,并通过fd2将读出的数据写入到新文件中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd1 = open("./english.txt" , O_RDONLY); if (fd1 == -1 ) { perror("open-readfile" ); return -1 ; } int fd2 = open("copy.txt" , O_WRONLY|O_CREAT, 0664 ); if (fd2 == -1 ) { perror("open-writefile" ); return -1 ; } char buf[4096 ]; int len = -1 ; while ( (len = read(fd1, buf, sizeof (buf))) > 0 ) { write(fd2, buf, len); } close(fd1); close(fd2); return 0 ; }
2.3 lseek
系统函数 lseek 的功能是比较强大的, 我们既可以通过这个函数移动文件指针, 也可以通过这个函数进行文件的拓展。
1 2 3 4 5 #include <sys/types.h> #include <unistd.h> off_t lseek (int fd, off_t offset, int whence) ;
参数:
fd: 文件描述符, open() 函数的返回值, 通过这个参数定位打开的磁盘文件
offset: 偏移量,需要和第三个参数配合使用
whence: 通过这个参数指定函数实现什么样的功能
SEEK_SET: 从文件头部开始偏移 offset 个字节
SEEK_CUR: 从当前文件指针的位置向后偏移offset个字节
SEEK_END: 从文件尾部向后偏移offset个字节
返回值:
成功: 文件指针从头部开始计算总的偏移量
失败: -1
2.3.1 移动文件指针
通过对 lseek 函数第三个参数的设置, 经常使用该函数实现如下几个功能
2.3.2 文件拓展 假设使用一个下载软件进行一个大文件下载,但是磁盘很紧张,如果不能马上将文件下载到本地,磁盘空间就可能被其他文件占用了,导致下载软件下载的文件无处存放。那么这个文件怎么解决呢?
我们可以在开始下载的时候先进行文件拓展,将一些字符写入到目标文件中,让拓展的文件和即将被下载的文件一样大,这样磁盘空间就被成功抢到手,软件就可以下载对应的文件了。
使用 lseek 函数进行文件拓展必须要满足一下条件:
文件指针必须要偏移到文件尾部之后, 多出来的就需要被填充的部分。
文件拓展举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () { int fd = open("hello.txt" , O_RDWR); if (fd == -1 ) { perror("open" ); return -1 ; } lseek(fd, 1000 , SEEK_END); write(fd, " " , 1 ); close(fd); return 0 ; }
查看执行执行的效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ gcc lseek.c $ ll -rwxrwxr-x 1 robin robin 8808 May 6 2019 a.out* -rwxrwxr-x 1 robin robin 1013 May 6 2019 hello.txt* -rw-rw-r-- 1 robin robin 299 May 6 2019 lseek.c $ ./a.out $ ll -rwxrwxr-x 1 robin robin 8808 May 6 2019 a.out* -rwxrwxr-x 1 robin robin 2014 Jan 30 17:39 hello.txt* -rw-rw-r-- 1 robin robin 299 May 6 2019 lseek.c
2.4 truncate/ftruncate
truncate/ftruncate 这两个函数的功能是一样的,可以对文件进行拓展也可以截断文件。
1 2 3 4 5 6 7 8 #include <unistd.h> #include <sys/types.h> int truncate (const char *path, off_t length) ;int ftruncate (int fd, off_t length) ;
参数:
path: 要拓展/截断的文件的文件名
fd: 文件描述符, open() 得到的
length: 文件的最终大小
文件原来size > length,文件被截断, 尾部多余的部分被删除, 文件最终长度为length
文件原来size < length,文件被拓展, 文件最终长度为length
返回值: 成功返回0; 失败返回值-1
truncate() 和 ftruncate() 两个函数的区别在于一个使用文件名一个使用文件描述符操作文件, 功能相同。
2.5 perror
在查看Linux系统函数的时候, 我们可以发现一个规律:
1 2 3 4 5 RETURN VALUE On success, zero is returned. On error, -1 is returned, and errno is set appropriately. 如果成功,则返回0。出现错误时,返回-1,并给errno设置一个适当的值。
errno是一个全局变量,只要调用的Linux系统函数有异常(返回-1)错误对应的错误号就会被设置给这个全局变量。 /usr/include/asm-generic/errno-base.h/usr/include/asm-generic/errno.h
得到错误号,去查询对应的头文件是非常不方便的,我们可以通过 perror 函数将错误号对应的描述信息打印出来
1 2 3 #include <stdio.h> void perror (const char *s) ;
举例: 使用 perrno 打印错误信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () { int fd = open("hello.txt" , O_RDWR|O_EXCL|O_CREAT, 0777 ); if (fd == -1 ) { perror("open" ); return -1 ; } close(fd); return 0 ; }
编译并执行程序
1 2 3 $ gcc open.c $ ./a.out open: File exists
2.6 错误号 为了方便查询, 特将全局变量 errno 和错误信息描述的对照关系贴出:
2.6.1 Part1 信息来自头文件: /usr/include/asm-generic/errno-base.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #define EPERM 1 #define ENOENT 2 #define ESRCH 3 #define EINTR 4 #define EIO 5 #define ENXIO 6 #define E2BIG 7 #define ENOEXEC 8 #define EBADF 9 #define ECHILD 10 #define EAGAIN 11 #define ENOMEM 12 #define EACCES 13 #define EFAULT 14 #define ENOTBLK 15 #define EBUSY 16 #define EEXIST 17 #define EXDEV 18 #define ENODEV 19 #define ENOTDIR 20 #define EISDIR 21 #define EINVAL 22 #define ENFILE 23 #define EMFILE 24 #define ENOTTY 25 #define ETXTBSY 26 #define EFBIG 27 #define ENOSPC 28 #define ESPIPE 29 #define EROFS 30 #define EMLINK 31 #define EPIPE 32 #define EDOM 33 #define ERANGE 34
2.6.2 Part2 信息来自头文件: /usr/include/asm-generic/errno.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 #define EDEADLK 35 #define ENAMETOOLONG 36 #define ENOLCK 37 #define ENOSYS 38 #define ENOTEMPTY 39 #define ELOOP 40 #define EWOULDBLOCK EAGAIN #define ENOMSG 42 #define EIDRM 43 #define ECHRNG 44 #define EL2NSYNC 45 #define EL3HLT 46 #define EL3RST 47 #define ELNRNG 48 #define EUNATCH 49 #define ENOCSI 50 #define EL2HLT 51 #define EBADE 52 #define EBADR 53 #define EXFULL 54 #define ENOANO 55 #define EBADRQC 56 #define EBADSLT 57 #define EDEADLOCK EDEADLK #define EBFONT 59 #define ENOSTR 60 #define ENODATA 61 #define ETIME 62 #define ENOSR 63 #define ENONET 64 #define ENOPKG 65 #define EREMOTE 66 #define ENOLINK 67 #define EADV 68 #define ESRMNT 69 #define ECOMM 70 #define EPROTO 71 #define EMULTIHOP 72 #define EDOTDOT 73 #define EBADMSG 74 #define EOVERFLOW 75 #define ENOTUNIQ 76 #define EBADFD 77 #define EREMCHG 78 #define ELIBACC 79 #define ELIBBAD 80 #define ELIBSCN 81 #define ELIBMAX 82 #define ELIBEXEC 83 #define EILSEQ 84 #define ERESTART 85 #define ESTRPIPE 86 #define EUSERS 87 #define ENOTSOCK 88 #define EDESTADDRREQ 89 #define EMSGSIZE 90 #define EPROTOTYPE 91 #define ENOPROTOOPT 92 #define EPROTONOSUPPORT 93 #define ESOCKTNOSUPPORT 94 #define EOPNOTSUPP 95 #define EPFNOSUPPORT 96 #define EAFNOSUPPORT 97 #define EADDRINUSE 98 #define EADDRNOTAVAIL 99 #define ENETDOWN 100 #define ENETUNREACH 101 #define ENETRESET 102 #define ECONNABORTED 103 #define ECONNRESET 104 #define ENOBUFS 105 #define EISCONN 106 #define ENOTCONN 107 #define ESHUTDOWN 108 #define ETOOMANYREFS 109 #define ETIMEDOUT 110 #define ECONNREFUSED 111 #define EHOSTDOWN 112 #define EHOSTUNREACH 113 #define EALREADY 114 #define EINPROGRESS 115 #define ESTALE 116 #define EUCLEAN 117 #define ENOTNAM 118 #define ENAVAIL 119 #define EISNAM 120 #define EREMOTEIO 121 #define EDQUOT 122 #define ENOMEDIUM 123 #define EMEDIUMTYPE 124 #define ECANCELED 125 #define ENOKEY 126 #define EKEYEXPIRED 127 #define EKEYREVOKED 128 #define EKEYREJECTED 129 #define EOWNERDEAD 130 #define ENOTRECOVERABLE 131 #define ERFKILL 132 #define EHWPOISON 133
3. 文件的属性信息 众所周知,Linux是一个基于文件的操作系统,因此作为文件本身也就有很多属性,如果想要查看某一个文件的属性有两种方式:命令和函数。stat。另外使用file命令也可以查看文件的一些属性信息。
3.1 file 命令
该命令用来识别文件类型,也可用来辨别一些文件的编码格式。它是通过查看文件的头部信息来获取文件类型,而不是像Windows通过扩展名来确定文件类型的。
命令语法如下:
file 命令的参数是可选项, 可以不加, 常用的参数如下表:
参数
功能
-b
只显示文件类型和文件编码, 不显示文件名
-i
显示文件的 MIME 类型
-F
设置输出字符串的分隔符
-L
查看软连接文件自身文件属性
3.1.1 查看文件类型和编码格式 使用不带任何选项的 file 命令,即可查看指定文件的类型和文件编码信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ file 11.txt 11.txt: empty $ file b.cpp b.cpp: C source , ASCII text robin@OS:~$ file test.cpp test.cpp: C source , UTF-8 Unicode (with BOM) text, with CRLF line terminators robin@OS:~$ file a.out a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, for GNU/Linux 2.6.32, BuildID[sha1]=5317ae9fba592bf583c4f680d8cc48a8b58c96a5, not stripped
3.1.2 只显示文件格式以及编码 使用-b参数,可以使 file 命令的输出不出现文件名,只显示文件格式以及编码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ file 11.txt -b empty $ file b.cpp -b C source , ASCII text robin@OS:~$ file test.cpp -b C source , UTF-8 Unicode (with BOM) text, with CRLF line terminators robin@OS:~$ file a.out -b ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, for GNU/Linux 2.6.32, BuildID[sha1]=5317ae9fba592bf583c4f680d8cc48a8b58c96a5, not stripped
3.1.3 显示文件的 MIME 类型 给file命令添加-i参数,可以输出文件对应的 MIME 类型的字符串。
MIME(Multipurpose Internet Mail Extensions)多用途互联网邮件扩展类型。浏览器会自动使用指定应用程序来打开。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ file occi.cpp -i occi.cpp: text/x-c; charset=utf-8 $ file fcgi.tar.gz -i fcgi.tar.gz: application/gzip; charset=binary $ file english.txt -i english.txt: text/plain; charset=utf-8 $ file demo.html -i demo.html: text/html; charset=us-ascii
3.1.4 设置输出分隔符 在 file 命令中,文件名和后边的属性信息默认使用冒号(:)分隔,我们可以通过 -F 参数修改分隔符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ file english.txt english.txt: UTF-8 Unicode text, with very long lines, with CRLF line terminators $ file english.txt -F "==>" english.txt==> UTF-8 Unicode text, with very long lines, with CRLF line terminators $ file english.txt -F '==>' english.txt==> UTF-8 Unicode text, with very long lines, with CRLF line terminators $ file english.txt -F = english.txt= UTF-8 Unicode text, with very long lines, with CRLF line terminators
3.1.5 查看软连接文件
软连接文件是一个特殊格式的文件, 查看这种格式的文件可以得到两种结果: 第一种是软连接文件本身的属性信息,另一种是链接文件指向的那个文件的属性信息。file 查看文件属性得到的是链接文件指向的文件的信息-L得到的链接文件自身的属性信息。
1 2 3 4 5 6 7 8 9 10 11 $ ll link.lnk lrwxrwxrwx 1 root root 24 Jan 25 17:27 link.lnk -> /root/luffy/onepiece.txt $ file link.lnk link.lnk: symbolic link to `/root/luffy/onepiece.txt' # 使用 file 查看链接文件自身属性信息, 添加参数 -L $ file link.lnk -L link.lnk: UTF-8 Unicode text
3.2 stat 命令 stat命令显示文件或目录的详细属性信息包括文件系统状态,比ls命令输出的信息更详细。
关于这个命令的可选参数如下表:
参数
功能
-f
不显示文件本身的信息,显示文件所在文件系统的信息
-L
查看软链接文件关联的文件的属性信息
-c
查看文件某个单个的属性信息
-t
简洁模式,只显示摘要信息,不显示属性描述
3.2.1 显示所有属性 1 2 3 4 5 6 7 8 9 $ stat english.txt File: 'english.txt' Size: 129567 Blocks: 256 IO Block: 4096 regular file Device: 801h/2049d Inode: 526273 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1001/ robin) Gid: ( 1001/ robin) Access: 2021-01-31 00:00:36.791490304 +0800 Modify: 2021-01-31 00:00:36.791490304 +0800 Change: 2021-01-31 00:00:36.791490304 +0800 Birth: -
在输出的信息中我们可以看到很多属性,
File: 文件名Size: 文件大小, 单位是字节Blocks: 文件使用的数据块总数IO Block:IO块大小regular file:文件的实际类型,文件类型不同,该关键字也会变化Device:设备编号Inode:Inode号,操作系统用inode编号来识别不同的文件,找到文件数据所在的block,读出数据。Links:硬链接计数Access:文件所有者+所属组用户+其他人对文件的访问权限Uid: 文件所有者名字和所有者IDGid:文件所有数组名字已经组IDAccess Time:表示文件的访问时间。当文件内容被访问时,这个时间被更新Modify Time:表示文件内容的修改时间,当文件的数据内容被修改时,这个时间被更新Change Time:表示文件的状态时间,当文件的状态被修改时,这个时间被更新,例如:文件的硬链接链接数,大小,权限,Blocks数等。Birth: 文件生成的日期
3.2.2 只显示系统信息 给 stat 命令添加 -f参数将只显示文件在文件系统中的相关属性信息, 文件自身属性不显示
1 2 3 4 5 6 $ stat luffy/ -f File: "luffy/" ID: 47d795d8889d00d3 Namelen: 255 Type: ext2/ext3 Block size: 4096 Fundamental block size: 4096 Blocks: Total: 10288179 Free: 8991208 Available: 8546752 Inodes: Total: 2621440 Free: 2515927
3.2.3 软连接文件 使用 stat 查看软链接类型的文件, 默认显示的是这个软链接文件的属性信息, 添加参数 -L 就可以查看这个软连接文件关联的文件的属性信息了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ls -l link.lnk lrwxrwxrwx 1 root root 24 Jan 25 17:27 link.lnk -> /root/luffy/onepiece.txt $ stat link.lnk File: ‘link.lnk’ -> ‘/root/luffy/onepiece.txt’ Size: 24 Blocks: 0 IO Block: 4096 symbolic link Device: fd01h/64769d Inode: 393832 Links: 1 Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2021-01-30 23:46:29.922760178 +0800 Modify: 2021-01-25 17:27:12.057386837 +0800 Change: 2021-01-25 17:27:12.057386837 +0800 Birth: - $ stat link.lnk -L File: ‘link.lnk’ Size: 3700 Blocks: 8 IO Block: 4096 regular file Device: fd01h/64769d Inode: 660353 Links: 2 Access: (0444/-r--r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2021-01-30 23:46:53.696723182 +0800 Modify: 2021-01-25 17:54:47.000000000 +0800 Change: 2021-01-26 11:57:00.587658977 +0800 Birth: -
3.2.4 简洁输出 使用 stat 进行简洁信息输出的可读性不是太好, 所有的属性描述都别忽略了, 如果只想得到属性值, 可以给该命令添加-t参数:
1 2 $ stat luffy/ -t luffy/ 4096 8 41fd 1001 1001 801 662325 8 0 0 1611659086 1580893020 1580893020 0 4096
3.2.5 单个属性输出 如果每次只想通过 stat 命令得到某一个文件属性, 可以给名添加 -c 参数。-c 后边即可。
属性对应的字符如下表:
格式化字符
功能
%a
文件的八进制访问权限(#和0是输出标准)
%A
人类可读形式的文件访问权限(rwx)
%b
已分配的块数量
%B
报告的每个块的大小(以字节为单位)
%C
SELinux 安全上下文字符串
%d
设备编号 (十进制)
%D
设备编号 (十六进制)
%F
文件类型
%g
文件所属组组ID
%G
文件所属组名字
%h
用连接计数
%i
inode编号
%m
挂载点
%n
文件名
%N
用引号括起来的文件名,并且会显示软连接文件引用的文件路径
%o
最佳I/O传输大小提示
%s
文件总大小, 单位为字节
%t
十六进制的主要设备类型,用于字符/块设备特殊文件
%T
十六进制的次要设备类型,用于字符/块设备特殊文件
%u
文件所有者ID
%U
文件所有者名字
%w
文件生成的日期 ,人类可识别的时间字符串 – 获取不到信息不显示
%W
文件生成的日期 ,自纪元以来的秒数 (参考 %X )– 获取不到信息不显示
%x
最后访问文件的时间, 人类可识别的时间字符串
%X
最后访问文件的时间, 自纪元以来的秒数(从1970.1.1开始到最后一次文件访问的总秒数)
%y
最后修改文件内容的时间, 人类可识别的时间字符串
%Y
最后修改文件内容的时间, 自纪元以来的秒数(参考 %X )
%z
最后修改文件状态的时间, 人类可识别的时间字符串
%Z
最后修改文件状态的时间, 自纪元以来的秒数(参考 %X )
仔细阅读上表可以知道:文件的每一个属性都有一个或者多个与之对应的格式化字符,这样就可以精确定位所需要的属性信息了,举几个例子作为参考:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ stat occi.cpp -c %a 644 $ stat occi.cpp -c %A -rw-r--r-- $ ll occi.cpp -rw-r--r-- 1 robin robin 1406 Jan 31 00:00 occi.cpp $ stat link.lnk -c %N 'link.lnk' -> '/home/robin/english.txt' $ stat link.lnk -c %y 2021-01-31 10:48:52.317846411 +0800
3.3 stat/lstat 函数 stat/lstat 函数的功能和 stat 命令的功能是一样的, 只不过是应用场景不同。
lstat(): 得到的是软连接文件本身的属性信息stat(): 得到的是软链接文件关联的文件的属性信息
1 2 3 4 5 6 7 #include <sys/types.h> #include <sys/stat.h> #include <unistd.h> int stat (const char *pathname, struct stat *buf) ;int lstat (const char *pathname, struct stat *buf) ;
参数:
pathname: 文件名, 要获取这个文件的属性信息
buf: 传出参数, 文件的信息被写入到了这块内存中
返回值: 函数调用成功返回 0,调用失败返回 -1
这个函数的第二个参数是一个结构体类型, 这个结构体相对复杂, 通过这个结构体可以存储得到的文件的所有属性信息, 结构体原型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct stat { dev_t st_dev; ino_t st_ino; mode_t st_mode; nlink_t st_nlink; uid_t st_uid; gid_t st_gid; dev_t st_rdev; off_t st_size; blksize_t st_blksize; blkcnt_t st_blocks; time_t st_atime; time_t st_mtime; time_t st_ctime; };
3.3.1 获取文件大小 下面调用 stat() 函数, 以代码的方式演示一下如何得到某个文件的大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <sys/stat.h> int main () { struct stat myst ; int ret = stat("./english.txt" , &myst); if (ret == -1 ) { perror("stat" ); return -1 ; } printf ("文件大小: %d\n" , (int )myst.st_size); return 0 ; }
3.3.2 获取文件类型 文件的类型信息存储在 struct stat 结构体的st_mode成员中, 它是一个 mode_t 类型, 本质上是一个16位的整数。man 2 stat)查询到。
相关的宏函数原型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 S_ISREG(m) is it a regular file? - 普通文件 S_ISDIR(m) directory? - 目录 S_ISCHR(m) character device? - 字符设备 S_ISBLK(m) block device? - 块设备 S_ISFIFO(m) FIFO (named pipe)? - 管道 S_ISLNK(m) symbolic link? (Not in POSIX.1 -1996. ) - 软连接 S_ISSOCK(m) socket? (Not in POSIX.1 -1996. ) - 本地套接字文件
在程序中通过宏函数判断文件类型, 实例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int main () { struct stat myst ; int ret = stat("./hello" , &myst); if (ret == -1 ) { perror("stat" ); return -1 ; } if (S_ISREG(myst.st_mode)) { printf ("这个文件是一个普通文件...\n" ); } if (S_ISDIR(myst.st_mode)) { printf ("这个文件是一个目录...\n" ); } if (S_ISLNK(myst.st_mode)) { printf ("这个文件是一个软连接文件...\n" ); } return 0 ; }
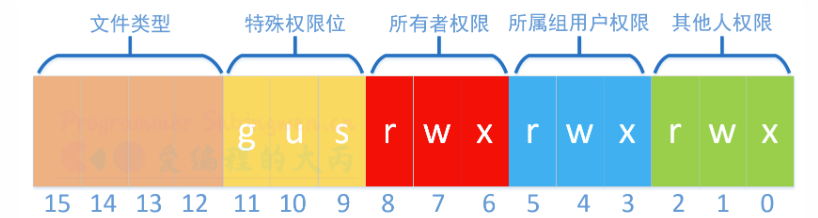
3.3.2 获取文件权限 用户对文件的操作权限也存储在 struct stat 结构体的st_mode成员中, 在这个16位的整数中不同用户的权限存储位置如下图
Linux 中为我们提供了用于不同用户不同权限判定使用的宏,具体信息如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 关于变量 st_mode: - st_mode -- 16位整数 ○ 0-2 bit -- 其他人权限 - S_IROTH 00004 读权限 100 - S_IWOTH 00002 写权限 010 - S_IXOTH 00001 执行权限 001 - S_IRWXO 00007 掩码, 过滤 st_mode中除其他人权限以外的信息 ○ 3-5 bit -- 所属组权限 - S_IRGRP 00040 读权限 - S_IWGRP 00020 写权限 - S_IXGRP 00010 执行权限 - S_IRWXG 00070 掩码, 过滤 st_mode中除所属组权限以外的信息 ○ 6-8 bit -- 文件所有者权限 - S_IRUSR 00400 读权限 - S_IWUSR 00200 写权限 - S_IXUSR 00100 执行权限 - S_IRWXU 00700 掩码, 过滤 st_mode中除文件所有者权限以外的信息 ○ 12-15 bit -- 文件类型 - S_IFSOCK 0140000 套接字 - S_IFLNK 0120000 符号链接(软链接) - S_IFREG 0100000 普通文件 - S_IFBLK 0060000 块设备 - S_IFDIR 0040000 目录 - S_IFCHR 0020000 字符设备 - S_IFIFO 0010000 管道 - S_IFMT 0170000 掩码,过滤 st_mode中除文件类型以外的信息 1111 1111 1111 1011 0000 0000 0000 0100 & ---------------------------------------- 0000 0000 0000 0000
通过仔细阅读上边提供的宏信息, 我们可以知道处理使用它们得到用户对文件的操作权限, 还可以用于判断文件的类型(判断文件类型的第二种方式),具体操作方式可以参考如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <sys/stat.h> int main () { struct stat myst ; int ret = stat("./hello" , &myst); if (ret == -1 ) { perror("stat" ); return -1 ; } printf ("文件大小: %d\n" , (int )myst.st_size); if (S_ISREG(myst.st_mode)) { printf ("这个文件是一个普通文件...\n" ); } if (S_ISDIR(myst.st_mode)) { printf ("这个文件是一个目录...\n" ); } if (S_ISLNK(myst.st_mode)) { printf ("这个文件是一个软连接文件...\n" ); } printf ("文件所有者对文件的操作权限: " ); if (myst.st_mode & S_IRUSR) { printf ("r" ); } if (myst.st_mode & S_IWUSR) { printf ("w" ); } if (myst.st_mode & S_IXUSR) { printf ("x" ); } printf ("\n" ); return 0 ; }
3.4 练习 掌握了如何通过 stat / lstat 函数获取文件相关属性之后,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 #include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <stdlib.h> #include <time.h> #include <pwd.h> #include <grp.h> int main (int argc, char * argv[]) { if (argc < 2 ) { printf ("./a.out filename\n" ); exit (1 ); } struct stat st ; int ret = stat(argv[1 ], &st); if (ret == -1 ) { perror("stat" ); exit (1 ); } char perms[11 ] = {0 }; switch (st.st_mode & S_IFMT) { case S_IFLNK: perms[0 ] = 'l' ; break ; case S_IFDIR: perms[0 ] = 'd' ; break ; case S_IFREG: perms[0 ] = '-' ; break ; case S_IFBLK: perms[0 ] = 'b' ; break ; case S_IFCHR: perms[0 ] = 'c' ; break ; case S_IFSOCK: perms[0 ] = 's' ; break ; case S_IFIFO: perms[0 ] = 'p' ; break ; default : perms[0 ] = '?' ; break ; } perms[1 ] = (st.st_mode & S_IRUSR) ? 'r' : '-' ; perms[2 ] = (st.st_mode & S_IWUSR) ? 'w' : '-' ; perms[3 ] = (st.st_mode & S_IXUSR) ? 'x' : '-' ; perms[4 ] = (st.st_mode & S_IRGRP) ? 'r' : '-' ; perms[5 ] = (st.st_mode & S_IWGRP) ? 'w' : '-' ; perms[6 ] = (st.st_mode & S_IXGRP) ? 'x' : '-' ; perms[7 ] = (st.st_mode & S_IROTH) ? 'r' : '-' ; perms[8 ] = (st.st_mode & S_IWOTH) ? 'w' : '-' ; perms[9 ] = (st.st_mode & S_IXOTH) ? 'x' : '-' ; int linkNum = st.st_nlink; char * fileUser = getpwuid(st.st_uid)->pw_name; char * fileGrp = getgrgid(st.st_gid)->gr_name; int fileSize = (int )st.st_size; char * time = ctime(&st.st_mtime); char mtime[512 ] = {0 }; strncpy (mtime, time, strlen (time)-1 ); char buf[1024 ]; sprintf (buf, "%s %d %s %s %d %s %s" , perms, linkNum, fileUser, fileGrp, fileSize, mtime, argv[1 ]); printf ("%s\n" , buf); return 0 ; }
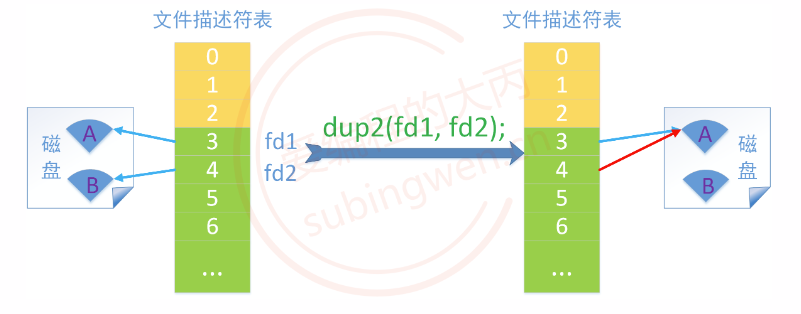
4. 文件描述符复制和重定向 在Linux中只要调用open()函数就可以给被操作的文件分配一个文件描述符dup, dup2, fcntl。
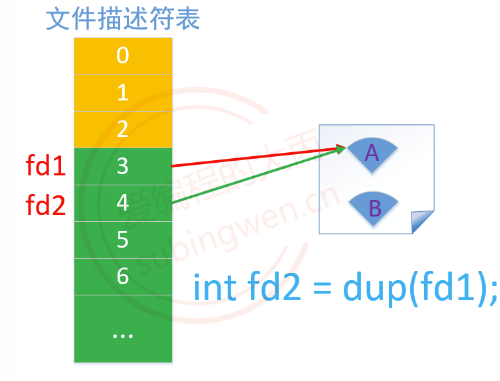
4.1 dup 4.1.1 函数详解 dup函数的作用是复制文件描述符,这样就有多个文件描述符可以指向同一个文件了。
1 2 3 #include <unistd.h> int dup (int oldfd) ;
下图展示了 dup()函数具体行为, 这样不管使用 fd1还是使用fd2都可以对磁盘文件A进行操作了。
被复制出的新文件描述符是独立于旧的文件描述符的,二者没有连带关系。也就是说当旧的文件描述符被关闭了,复制出的新文件描述符还是可以继续使用的。
4.1.2 示例代码 下面的代码中演示了通过dup()函数进行文件描述符复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./mytest.txt" , O_RDWR|O_CREAT, 0664 ); if (fd == -1 ) { perror("open" ); exit (0 ); } printf ("fd: %d\n" , fd); const char * pt = "你好, 世界......" ; write(fd, pt, strlen (pt)); int newfd = dup(fd); printf ("newfd: %d\n" , newfd); close(fd); const char * ppt = "((((((((((((((((你要相信光!!!))))))))))))))))" ; write(newfd, ppt, strlen (ppt)); close(newfd); return 0 ; }
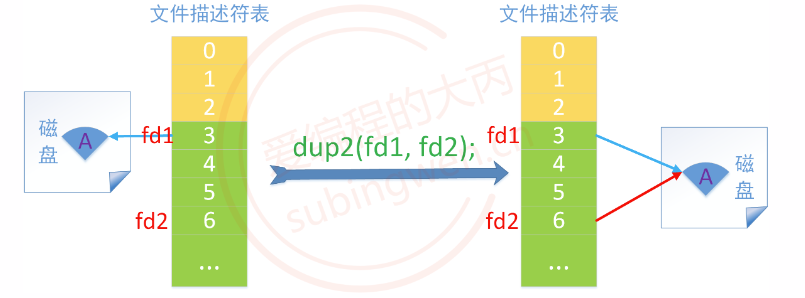
4.2 dup2 4.2.1 函数详解 dup2() 函数是 dup() 函数的加强版,基于dup2() 既可以进行文件描述符的复制, 也可以进行文件描述符的重定向。
1 2 3 4 5 6 7 8 9 10 #include <unistd.h> int dup2 (int oldfd, int newfd) ;
参数: oldfd和``newfd` 都是文件描述符
返回值: 函数调用成功返回新的文件描述符, 调用失败返回 -1
关于这个函数的两个参数虽然都是文件描述符,但是在使用过程中又对应了不同的场景,具体如下:
场景1:oldfd 对应磁盘文件 a.txt, newfd对应磁盘文件b.txt。newfd做了重定向,newfd 和文件 b.txt 断开关联, 相当于关闭了这个文件, 同时 newfd 指向了磁盘上的a.txt文件,最终 oldfd 和 newfd 都指向了磁盘文件 a.txt。
场景2:复制,newfd 指向了磁盘上的a.txt文件,最终 oldfd 和 newfd 都指向了磁盘文件 a.txt。
场景3:
4.2.2 示例代码
给dup2() 的第二个参数指定一个空闲的没被占用的文件描述符就可以进行文件描述符的复制了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./111.txt" , O_RDWR|O_CREAT, 0664 ); if (fd == -1 ) { perror("open" ); exit (0 ); } printf ("fd: %d\n" , fd); const char * pt = "你好, 世界......" ; write(fd, pt, strlen (pt)); int fd1 = 1023 ; dup2(fd, fd1); close(fd); const char * ppt = "(((((((((((((((你要相信光!!!)))))))))))))))))" ; write(fd1, ppt, strlen (ppt)); close(fd1); return 0 ; }
将两个有效的文件描述符分别传递给 dup2()函数,就可以实现文件描述符的重定向了。
如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./111.txt" , O_RDWR|O_CREAT, 0664 ); if (fd == -1 ) { perror("open" ); exit (0 ); } printf ("fd: %d\n" , fd); const char * pt = "你好, 世界......" ; write(fd, pt, strlen (pt)); int fd1 = open("./222.txt" , O_RDWR|O_CREAT, 0664 ); if (fd1 == -1 ) { perror("open1" ); exit (0 ); } dup2(fd, fd1); close(fd); const char * ppt = "(((((((((((((((你要相信光!!!)))))))))))))))" ; write(fd1, ppt, strlen (ppt)); close(fd1); return 0 ; }
4.3 fcntl 4.3.1 函数详解 fcntl() 是一个变参函数, 并且是多功能函数文件描述符的复制和获取/设置已打开的文件属性。
1 2 3 4 5 #include <unistd.h> #include <fcntl.h> int fcntl (int fd, int cmd, ... ) ;
参数:
fd: 要操作的文件描述符
cmd: 通过该参数控制函数要实现什么功能
返回值:函数调用失败返回 -1,调用成功,返回正确的值:
参数 cmd = F_DUPFD:返回新的被分配的文件描述符
参数 cmd = F_GETFL:返回文件的flag属性信息
fcntl() 函数的 cmd 可使用的参数列表:
参数 cmd 的取值
功能描述
F_DUPFD
复制一个已经存在的文件描述符
F_GETFL
获取文件的状态标志
F_SETFL
设置文件的状态标志
文件的状态标志指的是在使用 open() 函数打开文件的时候指定的 flags 属性, 也就是第二个参数
1 int open (const char *pathname, int flags) ;
下表中列出了一些常用的文件状态标志:
文件状态标志
说明
O_RDONLY
只读打开
O_WRONLY
只写打开
O_RDWR
读、写打开
O_APPEND
追加写
O_NONBLOCK
非阻塞模式
O_SYNC
等待写完成(数据和属性)
O_ASYNC
异步I/O
O_RSYNC
同步读和写
4.3.2 复制文件描述符 使用 fcntl() 函数进行文件描述符复制, 第二个参数 cmd 需要指定为 F_DUPFD(这是个变参函数其他参数不需要指定)。
1 int newfd = fcntl(fd, F_DUPFD);
使用 fcntl() 复制文件描述符, 函数返回值为新分配的文件描述符,示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./mytest.txt" , O_RDWR|O_CREAT, 0664 ); if (fd == -1 ) { perror("open" ); exit (0 ); } printf ("fd: %d\n" , fd); const char * pt = "你好, 世界......" ; write(fd, pt, strlen (pt)); int newfd = fcntl(fd, F_DUPFD); printf ("newfd: %d\n" , newfd); close(fd); const char * ppt = "((((((((((((((((((((((骚年,你要相信光!!!))))))))))))))))))))))" ; write(newfd, ppt, strlen (ppt)); close(newfd); return 0 ; }
4.3.3 设置文件状态标志 通过 open()函数打开文件之后, 文件的flag属性就已经被确定下来了fcntl()函数实现注意: 不是所有的flag 属性都能被动态修改, 只能修改如下状态标志: O_APPEND, O_NONBLOCK, O_SYNC, O_ASYNC, O_RSYNC等。
得到已打开的文件的状态标志,需要将 cmd 设置为 F_GETFL,得到的信息在函数的返回值中
1 int flag = fcntl(fd, F_GETFL);
设置已打开的文件的状态标志,需要将 cmd 设置为 F_SETFL,新的flag需要通过第三个参数传递给 fcntl() 函数
1 2 3 4 5 6 int flag = fcntl(fd, F_GETFL);flag = flag | O_APPEND; fcntl(fd, F_SETFL, flag);
举例: 通过fcntl()函数获取/设置已打开的文件属性,先来描述一下场景:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main () { int fd = open("./111.txt" , O_RDWR); if (fd == -1 ) { perror("open" ); exit (0 ); } printf ("fd: %d\n" , fd); int flag = fcntl(fd, F_GETFL); flag = flag | O_APPEND; fcntl(fd, F_SETFL, flag); const char * ppp = "((((((((((((((你要相信光!!!)))))))))))))))" ; write(fd, ppp, strlen (ppp)); close(fd); return 0 ; }
5. 目录遍历 Linux的目录是一个树状结构,了解数据结构的都明白,遍历一棵树最简单的方式是递归。
Linux给我们提供了相关的目录遍历的函数,分别为:opendir(), readdir(), closedir()。
5.1 目录三剑客 5.1.1 opendir 在目录操作之前必须要先通过 opendir() 函数打开这个目录
1 2 3 4 5 #include <sys/types.h> #include <dirent.h> DIR *opendir (const char *name) ;
参数: name -> 要打开的目录的名字
返回值: DIR*, 结构体类型指针。打开成功返回目录的实例,打开失败返回 NULL
5.1.2 readdir 目录打开之后,就可以通过 readdir() 函数遍历目录中的文件信息了。
1 2 3 4 #include <dirent.h> struct dirent *readdir (DIR *dirp) ;
参数:dirp -> opendir() 函数的返回值
返回值:函数调用成功,返回读到的文件的信息,
函数返回值 struct dirent 结构体原型如下:
1 2 3 4 5 6 7 struct dirent { ino_t d_ino; off_t d_off; unsigned short d_reclen; unsigned char d_type; char d_name[256 ]; };
关于结构体中的文件类型d_type,可使用的宏值如下:
DT_BLK:块设备文件DT_CHR:字符设备文件DT_DIR:目录文件DT_FIFO :管道文件DT_LNK:软连接文件DT_REG:普通文件DT_SOCK:本地套接字文件DT_UNKNOWN:无法识别的文件类型
那么,如何通过 readdir() 函数遍历某一个目录中的文件呢?
1 2 3 4 5 6 7 8 DIR* dir = opendir("/home/test" ); struct dirent * ptr =NULL ;while ( (ptr=readdir(dir)) != NULL ){ ....... }
5.1.3 closedir 目录操作完毕之后, 需要通过 closedir()关闭通过opendir()得到的实例,释放资源。
1 2 3 int closedir (DIR *dirp) ;
参数:dirp-> opendir() 函数的返回值
返回值: 目录关闭成功返回0, 失败返回 -1
5.2 遍历目录 5.2.1 遍历单层目录 如果只遍历单层目录是不需要递归的,按照上边介绍的函数的使用方法,依次继续调用即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <dirent.h> int main (int argc, char * argv[]) { DIR* dir = opendir(argv[1 ]); if (dir == NULL ) { perror("opendir" ); return -1 ; } int count = 0 ; while (1 ) { struct dirent * ptr = if (ptr == NULL ) { printf ("目录读完了...\n" ); break ; } if (ptr->d_type == DT_REG) { char * p = strstr (ptr->d_name, ".mp3" ); if (p != NULL && *(p+4 ) == '\0' ) { count++; printf ("file %d: %s\n" , count, ptr->d_name); } } } printf ("%s目录中mp3文件的个数: %d\n" , argv[1 ], count); closedir(dir); return 0 ; }
编译名执行程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ gcc filenum.c $ ./a.out . file 1: 1.mp3 目录读完了... .目录中mp3文件的个数: 1 $ ./a.out ./sub/ file 1: 3.mp3 file 2: 1.mp3 file 3: 5.mp3 file 4: 4.mp3 file 5: 2.mp3 目录读完了... ./sub/目录中mp3文件的个数: 5
5.2.2 遍历多层目录 Linux 的目录是树状结构,遍历每层目录的方式是一样的,也就是说最简单的遍历方式是递归。
示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <dirent.h> int getMp3Num (const char * path) { DIR* dir = opendir(path); if (dir == NULL ) { perror("opendir" ); return 0 ; } struct dirent * ptr =NULL ; int count = 0 ; while ((ptr = readdir(dir)) != NULL ) { if (strcmp (ptr->d_name, "." )==0 || strcmp (ptr->d_name, ".." ) == 0 ) { continue ; } if (ptr->d_type == DT_DIR) { char newPath[1024 ]; sprintf (newPath, "%s/%s" , path, ptr->d_name); count += getMp3Num(newPath); } else if (ptr->d_type == DT_REG) { char * p = strstr (ptr->d_name, ".mp3" ); if (p != NULL && *(p+4 ) == '\0' ) { count++; printf ("%s/%s\n" , path, ptr->d_name); } } } closedir(dir); return count; } int main (int argc, char * argv[]) { if (argc < 2 ) { printf ("./a.out path\n" ); return 0 ; } int num = getMp3Num(argv[1 ]); printf ("%s 目录中mp3文件个数: %d\n" , argv[1 ], num); return 0 ; }
编译并运行程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 $ gcc filenum.c $ ./a.out abc abc/sub/3.mp3 abc/sub/1.mp3 abc/sub/5.mp3 abc/sub/4.mp3 abc/sub/2.mp3 abc/sub/music/test2.mp3 abc/sub/music/test3.mp3 abc/sub/music/test1.mp3 abc/hello.mp3 abc 目录中mp3文件个数: 9
5.3 scandir函数 也可使用scandir()函数进行目录的遍历(只遍历指定目录,不进入到子目录中进行递归遍历)
/
1 2 3 4 5 6 7 8 / 函数原型 #include <dirent.h> int scandir (const char *dirp, struct dirent ***namelist, int (*filter)(const struct dirent *), int (*compar)(const struct dirent **, const struct dirent **)) ;int alphasort (const struct dirent **a, const struct dirent **b) ;int versionsort (const struct dirent **a, const struct dirent **b) ;
参数:
dirp: 需要遍历的目录的名字
namelist: 三级指针, 传出参数, 需要在指向的地址中存储遍历目录得到的所有文件的信息
在函数内部会给这个指针指向的地址分配内存,要注意在程序中释放内存
filter: 函数指针, 指针指向的函数就是回调函数, 需要在自定义函数中指定如果过滤目录中的文件
如果不对目录中的文件进行过滤, 该函数指针指定为NULL即可
如果自己指定过滤函数, 满足条件要返回1, 否则返回 0
compar: 函数指针, 对过滤得到的文件进行排序, 可以使用提供的两种排序方式:
alphasort: 根据文件名进行排序
versionsort: 根据版本进行排序
返回值: 函数执行成功返回找到的匹配成功的文件的个数,如果失败返回-1。
5.3.1 文件过滤 scandir() 可以让使用者自定义文件的过滤方式, 然后将过滤函数的地址传递给 scandir() 的第三个参数
1 2 3 int (*filter)(const struct dirent *);
基于这个函数指针定义的函数就可以称之为回调函数,scandir() 调用,因此这个函数的实参也是由 scandir() 函数提供的,作为回调函数的编写人员,只需搞清这个参数的含义是什么,然后在函数体中直接使用即可。
假设判断目录中某一个文件是否为Mp3格式
1 2 3 4 5 6 7 8 9 10 11 12 int isMp3 (const struct dirent *ptr) { if (ptr->d_type == DT_REG) { char * p = strstr (ptr->d_name, ".mp3" ); if (p != NULL && *(p+4 ) == '\0' ) { return 1 ; } } return 0 ; }
5.3.2 遍历目录 了解了 scandir() 函数的使用后,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <dirent.h> int isMp3 (const struct dirent *ptr) { if (ptr->d_type == DT_REG) { char * p = strstr (ptr->d_name, ".mp3" ); if (p != NULL && *(p+4 ) == '\0' ) { return 1 ; } } return 0 ; } int main (int argc, char * argv[]) { if (argc < 2 ) { printf ("./a.out path\n" ); return 0 ; } struct dirent **namelist =NULL ; int num = scandir(argv[1 ], &namelist, isMp3, alphasort); for (int i=0 ; i<num; ++i) { printf ("file %d: %s\n" , i, namelist[i]->d_name); free (namelist[i]); } free (namelist); return 0 ; }
再解析一下 scandir() 的第二个参数,传递的是一个二级指针的地址:
1 2 struct dirent **namelist =NULL ;int num = scandir(argv[1 ], &namelist, isMp3, alphasort);
那么在这个 namelist 中存储的什么类型的数据呢?struct dirent **namelist 指向的什么类型的数据?
答案: 指向的是一个指针数组 struct dirent *namelist[]
数组元素的个数就是遍历的目录中的文件个数
数组的每个元素都是指针类型: struct dirent *scandir() 函数分配的, 因此在使用完毕之后需要释放内存