1. 自动类型推导 1.1 auto
C++11之前auto和static是对应的,表示变量是自动存储的,但是非static的局部变量默认都是自动存储的,因此这个关键字变得非常鸡肋,
1.1.1 推导规则
使用auto声明的变量必须要进行初始化,以让编译器推导出它的实际类型,在编译时将auto占位符替换为真正的类型。
当变量不是指针或者引用类型时,推导的结果中不会保留const、volatile关键字
当变量是指针或者引用类型时,推导的结果中会保留const、volatile关键字
1.1.2 auto的限制
不能作为函数参数使用。因为只有在函数调用的时候才会给函数参数传递实参,auto要求必须要给修饰的变量赋值,因此二者矛盾。
1 2 3 4 int func (auto a, auto b) cout << "a: " << a <<", b: " << b << endl; }
不能使用auto关键字定义数组
1 2 3 4 5 6 7 int func () int array[] = {1 ,2 ,3 ,4 ,5 }; auto t1 = array; auto t2[] = array; auto t3[] = {1 ,2 ,3 ,4 ,5 };; }
无法使用auto推导出模板参数
1 2 3 4 5 6 7 8 9 template <typename T>struct Test {}int func () Test<double > t; Test<auto > t1 = t; return 0 ; }
1.1.3 auto的应用 下面列举几个比较常用的场景:
用于STL的容器遍历。
在C++11之前,定义了一个stl容器之后,遍历的时候常常会写出这样的代码:
1 2 3 4 5 6 7 8 9 10 11 #include <map> int main () map<int , string> person; map<int , string>::iterator it = person.begin (); for (; it != person.end (); ++it) { } return 0 ; }
可以看到在定义迭代器变量 it 的时候代码是很长的,写起来就很麻烦,使用了auto之后,就变得清爽了不少:
1 2 3 4 5 6 7 8 9 10 11 #include <map> int main () map<int , string> person; for (auto it = person.begin (); it != person.end (); ++it) { } return 0 ; }
用于泛型编程
在使用模板的时候,很多情况下我们不知道变量应该定义为什么类型,比如下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <string> using namespace std;class T1 { public : static int get () { return 10 ; } }; class T2 { public : static string get () { return "hello, world" ; } }; template <class A >void func (void ) auto val = A::get (); cout << "val: " << val << endl; } int main () func <T1>(); func <T2>(); return 0 ; }
在这个例子中定义了泛型函数func,在函数中调用了类A的静态方法 get() ,这个函数的返回值是不能确定的,如果不使用auto,就需要再定义一个模板参数,并且在外部调用时手动指定get的返回值类型,具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <string> using namespace std;class T1 { public : static int get () { return 0 ; } }; class T2 { public : static string get () { return "hello, world" ; } }; template <class A , typename B> void func (void ) B val = A::get (); cout << "val: " << val << endl; } int main () func <T1, int >(); func <T2, string>(); return 0 ; }
1.1.4 范围for 对应基于范围的for循环来说,冒号后边的表达式只会被执行一次。在得到遍历对象之后会先确定好迭代的范围,基于这个范围直接进行遍历。如果是普通的for循环,在每次迭代的时候都需要判断是否已经到了结束边界。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> #include <vector> using namespace std;vector<int > v{ 1 ,2 ,3 ,4 ,5 ,6 }; vector<int >& getRange () cout << "get vector range..." << endl; return v; } int main (void ) for (auto val : getRange ()) { cout << val << " " ; } cout << endl; return 0 ; }
1 2 get vector range... 1 2 3 4 5 6
1.2 decltype
在某些情况下,不需要或者不能定义变量,但是希望得到某种类型,这时候就可以使用C++11提供的decltype关键字了,它的作用是在编译器编译的时候推导出一个表达式的类型
decltype 是“declare type”的缩写,意思是“声明类型”。编译期完成的,它只是用于表达式类型的推导,并不会计算表达式的值。
一组简单的例子:
1 2 3 4 int a = 10 ;decltype (a) b = 99 ; decltype (a+3.14 ) c = 52.13 ; decltype (a+b*c) d = 520.1314 ;
可以看到decltype推导的表达式可简单可复杂,在这一点上auto是做不到的,auto只能推导已初始化的变量类型。
1.2.1 推导规则 通过上面的例子我们初步感受了一下 decltype 的用法,但不要认为 decltype 就这么简单,在它简单的背后隐藏着很多的细节
表达式为普通变量或者普通表达式或者类表达式,在这种情况下,使用decltype推导出的类型和表达式的类型是一致的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <string> using namespace std;class Test { public : string text; static const int value = 110 ; }; int main () int x = 99 ; const int &y = x; decltype (x) a = x; decltype (y) b = x; decltype (Test::value) c = 0 ; Test t; decltype (t.text) d = "hello, world" ; return 0 ; }
变量a被推导为 int类型
变量b被推导为 const int &类型
变量c被推导为 const int类型
变量d被推导为 string类型
表达式是函数调用,使用decltype推导出的类型和函数返回值一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Test {...};int func_int () int & func_int_r () int && func_int_rr () const int func_cint () const int & func_cint_r () const int && func_cint_rr () const Test func_ctest () int n = 100 ;decltype (func_int ()) a = 0 ; decltype (func_int_r ()) b = n; decltype (func_int_rr ()) c = 0 ; decltype (func_cint ()) d = 0 ; decltype (func_cint_r ()) e = n; decltype (func_cint_rr ()) f = 0 ; decltype (func_ctest ()) g = Test ();
变量a被推导为 int类型
变量b被推导为 int&类型
变量c被推导为 int&&类型
变量d被推导为 int类型
变量e被推导为 const int &类型
变量f被推导为 const int &&类型
变量g被推导为 const Test类型
函数 func_cint() 返回的是一个纯右值(在表达式执行结束后不再存在的数据,也就是临时性的数据)对于纯右值而言,只有类类型可以携带const、volatile限定符,除此之外需要忽略掉这两个限定符
表达式是一个左值,或者被括号( )包围,使用 decltype推导出的是表达式类型的引用(如果有const、volatile限定符不能忽略)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> #include <vector> using namespace std;class Test { public : int num; }; int main () const Test obj; decltype (obj.num) a = 0 ; decltype ((obj.num)) b = a; int n = 0 , m = 0 ; decltype (n + m) c = 0 ; decltype (n = n + m) d = n; return 0 ; }
obj.num 为类的成员访问表达式,符合场景1,因此 a 的类型为int
obj.num 带有括号,符合场景3,因此b 的类型为 const int&。
n+m 得到一个右值,符合场景1,因此c的类型为 int
n=n+m 得到一个左值 n,符合场景3,因此d的类型为 int&
1.2.2 decltype的应用
关于decltype的应用多出现在泛型编程中。比如我们编写一个类模板,在里边添加遍历容器的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <list> using namespace std;template <class T >class Container { public : void func (T& c) { for (m_it = c.begin (); m_it != c.end (); ++m_it) { cout << *m_it << " " ; } cout << endl; } private : ??? m_it; }; int main () const list<int > lst; Container<const list<int >> obj; obj.func (lst); return 0 ; }
在程序的???行出了问题,关于迭代器变量一共有两种类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <list> #include <iostream> using namespace std;template <class T >class Container { public : void func (T& c) { for (m_it = c.begin (); m_it != c.end (); ++m_it) { cout << *m_it << " " ; } cout << endl; } private : decltype (T ().begin ()) m_it; }; int main () const list<int > lst{ 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; Container<const list<int >> obj; obj.func (lst); return 0 ; }
1.3 返回类型后置
在泛型编程中,可能需要通过参数的运算来得到返回值的类型
比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;template <typename R, typename T, typename U>R add (T t, U u) return t + u; } int main () int x = 520 ; double y = 13.14 ; auto z = add <decltype (x + y)>(x, y); cout << "z: " << z << endl; return 0 ; }
关于返回值,从上面的代码可以推断出和表达式t+u的结果类型是一样的,因此可以通过decltype进行推导
因此如果要想解决这个问题就得直接在 add 函数身上做文章,先来看第一种写法:
1 2 3 4 5 template <typename T, typename U>decltype (t+u) add (T t, U u){ return t + u; }
当我们在编译器中将这几行代码改出来后就直接报错了,因为decltype中的 t 和 u 都是函数参数,直接这样写相当于变量还没有定义就直接用上了,这时候变量还不存在
C++11中增加了返回类型后置语法,说明白一点就是将decltype和auto结合起来完成返回类型的推导。
1 2 3 auto func (参数1 , 参数2 , ...) -> decltype (参数表达式)
auto 会追踪 decltype() 推导出的类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> using namespace std;template <typename T, typename U>auto add (T t, U u) -> decltype (t+u) return t + u; } int main () int x = 520 ; double y = 13.14 ; auto z = add (x, y); cout << "z: " << z << endl; return 0 ; }
为了进一步说明再看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> using namespace std;int & test (int &i) return i; } double test (double &d) d = d + 100 ; return d; } template <typename T>auto myFunc (T& t) -> decltype (test(t)) return test (t); } int main () int x = 520 ; double y = 13.14 ; auto z = myFunc (x); cout << "z: " << z << endl; auto z1 = myFunc (y); cout << "z1: " << z1 << endl; return 0 ; }
在这个例子中,通过decltype结合返回值后置语法很容易推导出来 test(t)函数可能出现的返回值类型,并将其作用到了函数myFunc()上。
// 输出结果
2.可调用对象包装器、绑定器
C++11通过提供std::function 和 std::bind统一了可调用对象的各种操作。
2.1 可调用对象包装器
std::function是可调用对象的包装器。它是一个类模板,可以容纳除了类成员(函数)指针之外的所有可调用对象。
2.1.1 基本用法 1 2 3 #include <functional> std::function<返回值类型(参数类型列表)> diy_name = 可调用对象;
下面的实例代码中演示了可调用对象包装器的基本使用方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <iostream> #include <functional> using namespace std;int add (int a, int b) cout << a << " + " << b << " = " << a + b << endl; return a + b; } class T1 { public : static int sub (int a, int b) { cout << a << " - " << b << " = " << a - b << endl; return a - b; } }; class T2 { public : int operator () (int a, int b) { cout << a << " * " << b << " = " << a * b << endl; return a * b; } }; int main (void ) function<int (int , int )> f1 = add; function<int (int , int )> f2 = T1::sub; T2 t; function<int (int , int )> f3 = t; f1 (9 , 3 ); f2 (9 , 3 ); f3 (9 , 3 ); return 0 ; }
输入结果如下:
1 2 3 9 + 3 = 12 9 - 3 = 6 9 * 3 = 27
通过测试代码可以得到结论:std::function可以将可调用对象进行包装,得到一个统一的格式
2.1.2 作为回调函数使用 因为回调函数本身就是通过函数指针实现的,使用对象包装器可以取代函数指针的作用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <functional> using namespace std;class A { public : A (const function<void ()>& f) : callback (f) { } void notify () { callback (); } private : function<void ()> callback; }; class B { public : void operator () () { cout << "我是要成为海贼王的男人!!!" << endl; } }; int main (void ) B b; A a (b) ; a.notify (); return 0 ; }
使用对象包装器std::function可以非常方便的将仿函数转换为一个函数指针
另外,使用std::function作为函数的传入参数,可以将定义方式不同的可调用对象进行统一的传递,这样大大增加了程序的灵活性。
2.2 绑定器
std::bind用来将可调用对象与其参数一起进行绑定。
通俗来讲有两大作用
将可调用对象与其参数一起绑定成一个仿函数。
将多元(参数个数为n,n>1)可调用对象转换为一元或者(n-1)元可调用对象,即只绑定部分参数。
1 2 3 4 5 auto f = std::bind (可调用对象地址, 绑定的参数/占位符);auto f = std::bind (类函数/成员地址, 类实例对象地址, 绑定的参数/占位符);
一个关于绑定器的实际使用的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <functional> using namespace std;void callFunc (int x, const function<void (int )>& f) if (x % 2 == 0 ) { f (x); } } void output (int x) cout << x << " " ; } void output_add (int x) cout << x + 10 << " " ; } int main (void ) auto f1 = bind (output, placeholders::_1); for (int i = 0 ; i < 10 ; ++i) { callFunc (i, f1); } cout << endl; auto f2 = bind (output_add, placeholders::_1); for (int i = 0 ; i < 10 ; ++i) { callFunc (i, f2); } cout << endl; return 0 ; }
测试代码输出的结果:
1 2 0 2 4 6 8 10 12 14 16 18
使用std::bind绑定器,在函数外部通过绑定不同的函数,控制了最后执行的结果。std::function
placeholders::_1是一个占位符,代表这个位置将在函数调用时被传入的第一个参数所替代。同样还有其他的占位符placeholders::_2、placeholders::_3、placeholders::_4、placeholders::_5等……
有了占位符的概念之后,使得std::bind的使用变得非常灵活:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <iostream> #include <functional> using namespace std;void output (int x, int y) cout << x << " " << y << endl; } int main (void ) bind (output, 1 , 2 )(); bind (output, placeholders::_1, 2 )(10 ); bind (output, 2 , placeholders::_1)(10 ); bind (output, 2 , placeholders::_2)(10 , 20 ); bind (output, placeholders::_1, placeholders::_2)(10 , 20 ); bind (output, placeholders::_2, placeholders::_1)(10 , 20 ); return 0 ; }
示例代码执行的结果:
1 2 3 4 5 6 1 2 10 2 2 10 2 20 10 20 20 10
通过测试可以看到,std::bind可以直接绑定函数的所有参数,也可以仅绑定部分参数。在绑定部分参数的时候,通过使用std::placeholders来决定空位参数将会属于调用发生时的第几个参数。
可调用对象包装器std::function是不能实现对类成员函数指针或者类成员指针的包装的,但是通过绑定器std::bind的配合之后,就可以完美的解决这个问题了
一个例子,然后解释细节:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <functional> using namespace std;class Test { public : void output (int x, int y) { cout << "x: " << x << ", y: " << y << endl; } int m_number = 100 ; }; int main (void ) Test t; function<void (int , int )> f1 = bind (&Test::output, &t, placeholders::_1, placeholders::_2); function<int &(void )> f2 = bind (&Test::m_number, &t); f1 (520 , 1314 ); f2 () = 2333 ; cout << "t.m_number: " << t.m_number << endl; return 0 ; }
示例代码输出的结果:
1 2 x: 520 , y: 1314 t.m_number: 2333
在用绑定器绑定类成员函数或者成员变量的时候需要将它们所属的实例对象一并传递到绑定器函数内部。f1的类型是function<void(int, int)>,通过使用std::bind将Test的成员函数output的地址和对象t绑定,并转化为一个仿函数并存储到对象f1中。
使用绑定器绑定的类成员变量m_number得到的仿函数被存储到了类型为function<int&(void)>的包装器对象f2中,并且可以在需要的时候修改这个成员。其中int是绑定的类成员的类型,并且允许修改绑定的变量,因此需要指定为变量的引用,由于没有参数因此参数列表指定为void。
示例程序中是使用function包装器保存了bind返回的仿函数,如果不知道包装器的模板类型如何指定,可以直接使用auto进行类型的自动推导,这样使用起来会更容易一些。
3. using 3.1 定义别名 1 2 3 4 5 typedef int (*func_ptr) (int , double ) using func_ptr1 = int (*)(int , double );
效果是一样的,但是使用using更加清晰
3.2 模板的别名 typedef对模板的别名简单并不容易实现
1 2 template <typename T>typedef map<int , T> type;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <functional> #include <map> using namespace std;template <typename T>struct MyMap { typedef map<int , T> type; }; int main (void ) MyMap<string>::type m; m.insert (make_pair (1 , "luffy" )); m.insert (make_pair (2 , "ace" )); MyMap<int >::type m1; m1.insert (1 , 100 ); m1.insert (2 , 200 ); return 0 ; }
在C++11中,新增了一个特性就是可以通过使用using来为一个模板定义别名
1 2 template <typename T>using mymap = map<int , T>;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <functional> #include <map> using namespace std;template <typename T>using mymap = map<int , T>;int main (void ) mymap<string> m; m.insert (make_pair (1 , "luffy" )); m.insert (make_pair (2 , "ace" )); mymap<int > m1; m1.insert (1 , 100 ); m1.insert (2 , 200 ); return 0 ; }
再次强调,using的语法和typedef是一样的,并不会创建新的类型,只是定义别名,
4. 智能指针的使用 4.1 shared_ptr 4.1.1 通过构造函数初始化
如果智能指针被初始化了一块有效内存,那么这块内存的引用计数+1,如果智能指针没有被初始化或者被初始化为nullptr空指针,引用计数不会+1。另外,不要使用一个原始指针初始化多个shared_ptr。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > ptr1 (new int (520 )) ; cout << "ptr1管理的内存引用计数: " << ptr1.use_count () << endl; shared_ptr<char > ptr2 (new char [12 ]) ; cout << "ptr2管理的内存引用计数: " << ptr2.use_count () << endl; shared_ptr<int > ptr3; cout << "ptr3管理的内存引用计数: " << ptr3.use_count () << endl; shared_ptr<int > ptr4 (nullptr ) ; cout << "ptr4管理的内存引用计数: " << ptr4.use_count () << endl; return 0 ; }
1 2 3 int *p = new int ;shared_ptr<int > p1 (p) ;shared_ptr<int > p2 (p) ;
4.1.2 通过拷贝和移动构造函数初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > ptr1 (new int (520 )) ; cout << "ptr1管理的内存引用计数: " << ptr1.use_count () << endl; shared_ptr<int > ptr2 (ptr1) ; cout << "ptr2管理的内存引用计数: " << ptr2.use_count () << endl; shared_ptr<int > ptr3 = ptr1; cout << "ptr3管理的内存引用计数: " << ptr3.use_count () << endl; shared_ptr<int > ptr4 (std::move(ptr1)) ; cout << "ptr4管理的内存引用计数: " << ptr4.use_count () << endl; std::shared_ptr<int > ptr5 = std::move (ptr2); cout << "ptr5管理的内存引用计数: " << ptr5.use_count () << endl; return 0 ; }
1 2 3 4 5 ptr1管理的内存引用计数: 1 ptr2管理的内存引用计数: 2 ptr3管理的内存引用计数: 3 ptr4管理的内存引用计数: 3 ptr5管理的内存引用计数: 3
4.1.3 通过std::make_shared初始化
通过C++提供的std::make_shared() 就可以完成内存对象的创建并将其初始化给智能指针
1 2 template < class T, class ... Args >shared_ptr<T> make_shared ( Args&&... args ) ;
T:模板参数的数据类型Args&&... args :要初始化的数据,如果是通过make_shared创建对象,需按照构造函数的参数列表指定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <string> #include <memory> using namespace std;class Test { public : Test () { cout << "construct Test..." << endl; } Test (int x) { cout << "construct Test, x = " << x << endl; } Test (string str) { cout << "construct Test, str = " << str << endl; } ~Test () { cout << "destruct Test ..." << endl; } }; int main () shared_ptr<int > ptr1 = make_shared <int >(520 ); cout << "ptr1管理的内存引用计数: " << ptr1.use_count () << endl; shared_ptr<Test> ptr2 = make_shared <Test>(); cout << "ptr2管理的内存引用计数: " << ptr2.use_count () << endl; shared_ptr<Test> ptr3 = make_shared <Test>(520 ); cout << "ptr3管理的内存引用计数: " << ptr3.use_count () << endl; shared_ptr<Test> ptr4 = make_shared <Test>("我是要成为海贼王的男人!!!" ); cout << "ptr4管理的内存引用计数: " << ptr4.use_count () << endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 ptr1管理的内存引用计数: 1 construct Test... ptr2管理的内存引用计数: 1 construct Test, x = 520 ptr3管理的内存引用计数: 1 construct Test, str = 我是要成为海贼王的男人!!! ptr4管理的内存引用计数: 1 destruct Test ... destruct Test ... destruct Test ...
4.1.4 通过 reset方法初始化 1 2 3 4 5 6 7 8 9 10 11 void reset () noexcept template < class Y >void reset ( Y* ptr ) template < class Y, class Deleter >void reset ( Y* ptr, Deleter d ) template < class Y, class Deleter, class Alloc >void reset ( Y* ptr, Deleter d, Alloc alloc )
ptr:指向要取得所有权的对象的指针
d:指向要取得所有权的对象的指针
aloc:内部存储所用的分配器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <string> #include <memory> using namespace std;int main () shared_ptr<int > ptr1 = make_shared <int >(520 ); shared_ptr<int > ptr2 = ptr1; shared_ptr<int > ptr3 = ptr1; shared_ptr<int > ptr4 = ptr1; cout << "ptr1管理的内存引用计数: " << ptr1.use_count () << endl; cout << "ptr2管理的内存引用计数: " << ptr2.use_count () << endl; cout << "ptr3管理的内存引用计数: " << ptr3.use_count () << endl; cout << "ptr4管理的内存引用计数: " << ptr4.use_count () << endl; ptr4.reset (); cout << "ptr1管理的内存引用计数: " << ptr1.use_count () << endl; cout << "ptr2管理的内存引用计数: " << ptr2.use_count () << endl; cout << "ptr3管理的内存引用计数: " << ptr3.use_count () << endl; cout << "ptr4管理的内存引用计数: " << ptr4.use_count () << endl; shared_ptr<int > ptr5; ptr5.reset (new int (250 )); cout << "ptr5管理的内存引用计数: " << ptr5.use_count () << endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 ptr1管理的内存引用计数: 4 ptr2管理的内存引用计数: 4 ptr3管理的内存引用计数: 4 ptr4管理的内存引用计数: 4 ptr1管理的内存引用计数: 3 ptr2管理的内存引用计数: 3 ptr3管理的内存引用计数: 3 ptr4管理的内存引用计数: 0 ptr5管理的内存引用计数: 1
对于一个未初始化的共享智能指针,可以通过reset方法来初始化,当智能指针中有值的时候,调用reset会使引用计数减1。
4.1.5 获取原始指针 1 2 T* get () const noexcept ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> #include <string> #include <memory> using namespace std;int main () int len = 128 ; shared_ptr<char > ptr (new char [len]) ; char * add = ptr.get (); memset (add, 0 , len); strcpy (add, "我是要成为海贼王的男人!!!" ); cout << "string: " << add << endl; shared_ptr<int > p (new int ) ; *p = 100 ; cout << p.get () << " " << *p << endl; return 0 ; }
1 2 string: 我是要成为海贼王的男人!!! 0000026F 48FE9410 100
4.2 weak_ptr
弱引用智能指针std::weak_ptr可以看做是shared_ptr的助手, std::weak_ptr没有重载操作符*和->,因为它不共享指针,不能操作资源,所以它的构造不会增加引用计数,析构也不会减少引用计数
4.2.1 基本使用方式 4.2.1.1 初始化 1 2 3 4 5 6 7 constexpr weak_ptr () noexcept weak_ptr (const weak_ptr& x) noexcept ;template <class U > weak_ptr (const weak_ptr<U>& x) noexcept ;template <class U > weak_ptr (const shared_ptr<U>& x) noexcept ;
具体使用方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > sp (new int ) ; weak_ptr<int > wp1; weak_ptr<int > wp2 (wp1) ; weak_ptr<int > wp3 (sp) ; weak_ptr<int > wp4; wp4 = sp; weak_ptr<int > wp5; wp5 = wp3; return 0 ; }
weak_ptr wp1;构造了一个空weak_ptr对象
weak_ptr wp2(wp1);通过一个空weak_ptr对象构造了另一个空weak_ptr对象
weak_ptr wp3(sp);通过一个shared_ptr对象构造了一个可用的weak_ptr实例对象
wp4 = sp;通过一个shared_ptr对象构造了一个可用的weak_ptr实例对象(这是一个隐式类型转换)
wp5 = wp3;通过一个weak_ptr对象构造了一个可用的weak_ptr实例对象
4.2.1.2 其他常用方法 4.2.1.2.1 use_count() 通过调用std::weak_ptr类提供的use_count()方法可以获得当前所观测资源的引用计数
1 2 3 long int use_count () const noexcept
修改一下上面的测试程序,添加打印资源引用计数的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > sp (new int ) ; weak_ptr<int > wp1; weak_ptr<int > wp2 (wp1) ; weak_ptr<int > wp3 (sp) ; weak_ptr<int > wp4; wp4 = sp; weak_ptr<int > wp5; wp5 = wp3; cout << "use_count: " << endl; cout << "wp1: " << wp1.use_count () << endl; cout << "wp2: " << wp2.use_count () << endl; cout << "wp3: " << wp3.use_count () << endl; cout << "wp4: " << wp4.use_count () << endl; cout << "wp5: " << wp5.use_count () << endl; return 0 ; }
测试程序输出的结果为:
1 2 3 4 5 6 use_count: wp1: 0 wp2: 0 wp3: 1 wp4: 1 wp5: 1
虽然弱引用智能指针wp3、wp4、wp5监测的资源是同一个,但是它的引用计数并没有发生任何的变化,也进一步证明了weak_ptr只是监测资源,并不管理资源。
4.2.1.2.2 expired() 通过调用std::weak_ptr类提供的expired()方法来判断观测的资源是否已经被释放,
1 2 3 bool expired () const noexcept
函数的使用方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > shared (new int (10 )) ; weak_ptr<int > weak (shared) ; cout << "1. weak " << (weak.expired () ? "is" : "is not" ) << " expired" << endl; shared.reset (); cout << "2. weak " << (weak.expired () ? "is" : "is not" ) << " expired" << endl; return 0 ; }
测试代码输出的结果:
1 2 1. weak is not expired2. weak is expired
weak_ptr监测的就是shared_ptr管理的资源shared.reset();之后管理的资源被释放,因此weak.expired()函数的结果返回true,表示监测的资源已经不存在了。
4.2.1.2.3 lock() 通过调用std::weak_ptr类提供的lock()方法来获取管理所监测资源的shared_ptr对象
1 2 shared_ptr<element_type> lock () const noexcept ;
函数的使用方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > sp1, sp2; weak_ptr<int > wp; sp1 = std::make_shared <int >(520 ); wp = sp1; sp2 = wp.lock (); cout << "use_count: " << wp.use_count () << endl; sp1.reset (); cout << "use_count: " << wp.use_count () << endl; sp1 = wp.lock (); cout << "use_count: " << wp.use_count () << endl; cout << "*sp1: " << *sp1 << endl; cout << "*sp2: " << *sp2 << endl; return 0 ; }
测试代码输出的结果为:
1 2 3 4 5 use_count: 2 use_count: 1 use_count: 2 *sp1: 520 *sp2: 520
sp2 = wp.lock();通过调用lock()方法得到一个用于管理weak_ptr对象所监测的资源的共享智能指针对象,使用这个对象初始化sp2,此时所监测资源的引用计数为2
sp1.reset();共享智能指针sp1被重置,weak_ptr对象所监测的资源的引用计数减1
sp1 = wp.lock();sp1重新被初始化,并且管理的还是weak_ptr对象所监测的资源,因此引用计数加1
共享智能指针对象sp1和sp2管理的是同一块内存,因此最终打印的内存中的结果是相同的,都是520
4.2.1.2.4 reset() 通过调用std::weak_ptr类提供的reset()方法来清空对象,使其不监测任何资源
函数的使用非常简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include <memory> using namespace std;int main () shared_ptr<int > sp (new int (10 )) ; weak_ptr<int > wp (sp) ; cout << "1. wp " << (wp.expired () ? "is" : "is not" ) << " expired" << endl; wp.reset (); cout << "2. wp " << (wp.expired () ? "is" : "is not" ) << " expired" << endl; return 0 ; }
测试代码输出的结果为:
1 2 1. wp is not expired2. wp is expired
weak_ptr对象sp被重置之后,变成了空对象,不再监测任何资源,因此wp.expired()返回true
4.2.2 返回管理this的shared_ptr 如果在一个类中编写了一个函数,通过这个得到管理当前对象的共享智能指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <memory> using namespace std;struct Test { shared_ptr<Test> getSharedPtr () { return shared_ptr <Test>(this ); } ~Test () { cout << "class Test is disstruct ..." << endl; } }; int main () shared_ptr<Test> sp1 (new Test) ; cout << "use_count: " << sp1.use_count () << endl; shared_ptr<Test> sp2 = sp1->getSharedPtr (); cout << "use_count: " << sp1.use_count () << endl; return 0 ; }
执行上面的测试代码,运行中会出现异常,在终端还是能看到对应的日志输出:
1 2 3 4 use_count: 1 use_count: 1 class Test is disstruct ...class Test is disstruct ...
通过输出的结果可以看到一个对象被析构了两次
这个问题可以通过weak_ptr来解决,通过wek_ptr返回管理this资源的共享智能指针对象shared_ptr。std::enable_shared_from_this<T>,这个类中有一个方法叫做shared_from_this(),通过这个方法可以返回一个共享智能指针,在函数的内部就是使用weak_ptr来监测this对象,并通过调用weak_ptr的lock()方法返回一个shared_ptr对象。
修改之后的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <memory> using namespace std;struct Test : public enable_shared_from_this<Test>{ shared_ptr<Test> getSharedPtr () { return shared_from_this (); } ~Test () { cout << "class Test is disstruct ..." << endl; } }; int main () shared_ptr<Test> sp1 (new Test) ; cout << "use_count: " << sp1.use_count () << endl; shared_ptr<Test> sp2 = sp1->getSharedPtr (); cout << "use_count: " << sp1.use_count () << endl; return 0 ; }
测试代码输出的结果为:
1 2 3 use_count: 1 use_count: 2 class Test is disstruct ...
注意:在调用enable_shared_from_this类的shared_from_this()方法之前weak_ptr对象,否则该函数无法返回一个有效的shared_ptr对象
4.2.3. 解决循环引用问题 智能指针如果循环引用会导致内存泄露,比如下面的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> #include <memory> using namespace std;struct TA ;struct TB ;struct TA { shared_ptr<TB> bptr; ~TA () { cout << "class TA is disstruct ..." << endl; } }; struct TB { shared_ptr<TA> aptr; ~TB () { cout << "class TB is disstruct ..." << endl; } }; void testPtr () shared_ptr<TA> ap (new TA) ; shared_ptr<TB> bp (new TB) ; cout << "TA object use_count: " << ap.use_count () << endl; cout << "TB object use_count: " << bp.use_count () << endl; ap->bptr = bp; bp->aptr = ap; cout << "TA object use_count: " << ap.use_count () << endl; cout << "TB object use_count: " << bp.use_count () << endl; } int main () testPtr (); return 0 ; }
测试程序输出的结果如下:
1 2 3 4 TA object use_count: 1 TB object use_count: 1 TA object use_count: 2 TB object use_count: 2
在测试程序中,共享智能指针ap、bp对TA、TB实例对象的引用计数变为2,在共享智能指针离开作用域之后引用计数只能减为1任意一个成员改为weak_ptr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> #include <memory> using namespace std;struct TA ;struct TB ;struct TA { weak_ptr<TB> bptr; ~TA () { cout << "class TA is disstruct ..." << endl; } }; struct TB { shared_ptr<TA> aptr; ~TB () { cout << "class TB is disstruct ..." << endl; } }; void testPtr () shared_ptr<TA> ap (new TA) ; shared_ptr<TB> bp (new TB) ; cout << "TA object use_count: " << ap.use_count () << endl; cout << "TB object use_count: " << bp.use_count () << endl; ap->bptr = bp; bp->aptr = ap; cout << "TA object use_count: " << ap.use_count () << endl; cout << "TB object use_count: " << bp.use_count () << endl; } int main () testPtr (); return 0 ; }
程序输出的结果:
1 2 3 4 5 6 TA object use_count: 1 TB object use_count: 1 TA object use_count: 2 TB object use_count: 1 class TB is disstruct ...class TA is disstruct ...
通过输出的结果可以看到类TA或者TB的对象被成功析构了。
上面程序中,在对类TA成员赋值时ap->bptr = bp;由于bptr是weak_ptr类型,这个赋值操作并不会增加引用计数,所以bp的引用计数仍然为1,在离开作用域之后bp的引用计数减为0,类TB的实例对象被析构。
在类TB的实例对象被析构的时候,内部的aptr也被析构,其对TA对象的管理解除,内存的引用计数减为1,当共享智能指针ap离开作用域之后,对TA对象的管理也解除了,内存的引用计数减为0,类TA的实例对象被析构。
5. constexpr 5.1 constexpr 介绍
在C++11中添加了一个新的关键字constexpr,这个关键字是用来修饰常量表达式的。
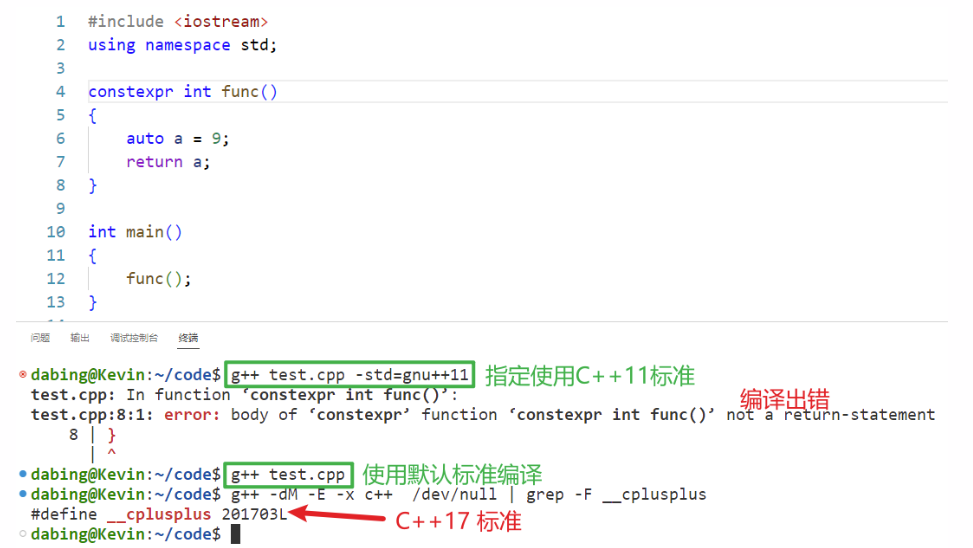
在介绍gcc/g++工作流程的时候说过,C++ 程序从编写完毕到执行分为四个阶段:预处理、 编译、汇编和链接4个阶段,得到可执行程序之后就可以运行了。
那么问题来了,编译器如何识别表达式是不是常量表达式呢?在C++11中添加了constexpr关键字之后就可以在程序中使用它来修饰常量表达式,用来提高程序的执行效率。凡是表达“只读”语义的场景都使用 const,表达“常量”语义的场景都使用 constexpr。
在定义常量时,const 和 constexpr 是等价的,都可以在程序的编译阶段计算出结果,例如:
1 2 3 4 5 6 const int m = f (); const int i=520 ; const int j=i+1 ; constexpr int i=520 ; constexpr int j=i+1 ;
对于 C++ 内置类型的数据,可以直接用 constexpr 修饰
1 2 3 4 5 6 constexpr struct Test { int id; int num; };
如果要定义一个结构体/类常量对象,可以这样写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct Test { int id; int num; }; int main () constexpr Test t{ 1 , 2 }; constexpr int id = t.id; constexpr int num = t.num; t.num += 100 ; cout << "id: " << id << ", num: " << num << endl; return 0 ; }
t.num += 100;的操作是错误的,对象t是常量,因此它的成员也是常量,常量是不能被修改的。
5.2 常量表达式函数
为了提高C++程序的执行效率 我们可以将程序中值不需要发生变化的变量定义为常量constexpr修饰函数的返回值,这种函数被称作常量表达式函数,这些函数主要包括以下几种:普通函数/类成员函数、类的构造函数、模板函数。
5.2.1 修饰函数 constexpr并不能修改任意函数的返回值,使这些函数成为常量表达式函数
函数必须要有返回值,并且return 返回的表达式必须是常量表达式。
1 2 3 4 5 6 7 8 9 10 11 12 13 constexpr void func1 () int a = 100 ; cout << "a: " << a << endl; } constexpr int func1 () int a = 100 ; return a; }
函数func1()没有返回值,不满足常量表达式函数要求
函数func2()返回值不是常量表达式,不满足常量表达式函数要求
由此可见在更新的C++标准里边放宽了对constexpr的语法限制。
函数在使用之前,必须有对应的定义语句。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> using namespace std;constexpr int func1 () int main () constexpr int num = func1 (); return 0 ; } constexpr int func1 () constexpr int a = 100 ; return a; }
在测试程序constexpr int num = func1();中,还没有定义func1()就直接调用了
整个函数的函数体中,不能出现非常量表达式之外的语句(using 指令、typedef 语句以及 static_assert 断言、return语句除外)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 constexpr int func1 () constexpr int a = 100 ; constexpr int b = 10 ; for (int i = 0 ; i < b; ++i) { cout << "i: " << i << endl; } return a + b; } constexpr int func2 () using mytype = int ; constexpr mytype a = 100 ; constexpr mytype b = 10 ; constexpr mytype c = a * b; return c - (a + b); }
因为func1()是一个常量表达式函数,在函数体内部是不允许出现非常量表达式以外的操作,因此函数体内部的for循环是一个非法操作。
以上三条规则不仅对应普通函数适用,对应类的成员函数也是适用的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Test { public : constexpr int func () { constexpr int var = 100 ; return 5 * var; } }; int main () Test t; constexpr int num = t.func (); cout << "num: " << num << endl; return 0 ; }
5.2.2 修饰模板函数
C++11 语法中,constexpr可以修饰函数模板,但由于模板中类型的不确定性,因此函数模板实例化后的模板函数是否符合常量表达式函数的要求也是不确定的。如果constexpr 修饰的模板函数实例化结果不满足常量表达式函数的要求,则 constexpr 会被自动忽略,即该函数就等同于一个普通函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> using namespace std;struct Person { const char * name; int age; }; template <typename T>constexpr T dispaly (T t) return t; } int main () struct Person p { "luffy" , 19 }; struct Person ret = dispaly (p); cout << "luffy's name: " << ret.name << ", age: " << ret.age << endl; constexpr int ret1 = dispaly (250 ); cout << ret1 << endl; constexpr struct Person p1 { "luffy" , 19 }; constexpr struct Person p2 = dispaly (p1); cout << "luffy's name: " << p2.name << ", age: " << p2.age << endl; return 0 ; }
在上面示例程序中定义了一个函数模板 display(),但由于其返回值类型未定,因此在实例化之前无法判断其是否符合常量表达式函数的要求:
struct Person ret = dispaly( p );由于参数p是变量,所以实例化后的函数不是常量表达式函数,此时 constexpr 是无效的constexpr int ret1 = dispaly(250);参数是常量,符合常量表达式函数的要求,此时 constexpr 是有效的constexpr struct Person p2 = dispaly(p1);参数是常量,符合常量表达式函数的要求,此时 constexpr 是有效的
5.2.3 修饰构造函数
如果想用直接得到一个常量对象,也可以使用constexpr修饰一个构造函数,这样就可以得到一个常量构造函数了。构造函数的函数体必须为空,并且必须采用初始化列表的方式为各个成员赋值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> using namespace std;struct Person { constexpr Person (const char * p, int age) :name(p), age(age) { } const char * name; int age; }; int main () constexpr struct Person p1 ("luffy" , 19 ); cout << "luffy's name: " << p1.name << ", age: " << p1.age << endl; return 0 ; }
6. 委托构造和继承构造函数 6.1 委托构造函数 委托构造函数允许使用同一个类中的一个构造函数调用其它的构造函数,从而简化相关变量的初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> using namespace std;class Test { public : Test () {}; Test (int max) { this ->m_max = max > 0 ? max : 100 ; } Test (int max, int min) { this ->m_max = max > 0 ? max : 100 ; this ->m_min = min > 0 && min < max ? min : 1 ; } Test (int max, int min, int mid) { this ->m_max = max > 0 ? max : 100 ; this ->m_min = min > 0 && min < max ? min : 1 ; this ->m_middle = mid < max && mid > min ? mid : 50 ; } int m_min; int m_max; int m_middle; }; int main () Test t (90 , 30 , 60 ) ; cout << "min: " << t.m_min << ", middle: " << t.m_middle << ", max: " << t.m_max << endl; return 0 ; }
在上面的程序中有三个构造函数,但是这三个函数中都有重复的代码,在C++11之前构造函数是不能调用构造函数的,加入了委托构造之后,我们就可以轻松地完成代码的优化了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> using namespace std;class Test { public : Test () {}; Test (int max) { this ->m_max = max > 0 ? max : 100 ; } Test (int max, int min):Test (max) { this ->m_min = min > 0 && min < max ? min : 1 ; } Test (int max, int min, int mid):Test (max, min) { this ->m_middle = mid < max && mid > min ? mid : 50 ; } int m_min; int m_max; int m_middle; }; int main () Test t (90 , 30 , 60 ) ; cout << "min: " << t.m_min << ", middle: " << t.m_middle << ", max: " << t.m_max << endl; return 0 ; }
在修改之后的代码中可以看到,重复的代码全部没有了,并且在一个构造函数中调用了其他的构造函数用于相关数据的初始化,相当于是一个链式调用。在使用委托构造函数的时候还需要注意一些几个问题:
这种链式的构造函数调用不能形成一个闭环(死循环),否则会在运行期抛异常。
如果要进行多层构造函数的链式调用,建议将构造函数的调用的写在初始列表中而不是函数体内部,否则编译器会提示形参的重复定义。
1 2 3 4 5 6 7 8 9 10 Test (int max){ this ->m_max = max > 0 ? max : 100 ; } Test (int max, int min){ Test (max); this ->m_min = min > 0 && min < max ? min : 1 ; }
在初始化列表中调用了代理构造函数初始化某个类成员变量之后,就不能在初始化列表中再次初始化这个变量了。
1 2 3 4 5 Test (int max, int min) : Test (max), m_max (max){ this ->m_min = min > 0 && min < max ? min : 1 ; }
6.2 继承构造函数
C++11中提供的继承构造函数可以让派生类直接使用基类的构造函数,而无需自己再写构造函数,尤其是在基类有很多构造函数的情况下,可以极大地简化派生类构造函数的编写。
没有继承构造函数之前的处理方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <string> using namespace std;class Base { public : Base (int i) :m_i (i) {} Base (int i, double j) :m_i (i), m_j (j) {} Base (int i, double j, string k) :m_i (i), m_j (j), m_k (k) {} int m_i; double m_j; string m_k; }; class Child : public Base{ public : Child (int i) :Base (i) {} Child (int i, double j) :Base (i, j) {} Child (int i, double j, string k) :Base (i, j, k) {} }; int main () Child c (520 , 13.14 , "i love you" ) ; cout << "int: " << c.m_i << ", double: " << c.m_j << ", string: " << c.m_k << endl; return 0 ; }
在子类中初始化从基类继承的类成员,需要在子类中重新定义和基类一致的构造函数,这是非常繁琐的
继承构造函数的使用方法是这样的:通过使用using 类名::构造函数名(其实类名和构造函数名是一样的)来声明使用基类的构造函数,这样子类中就可以不定义相同的构造函数了,直接使用基类的构造函数来构造派生类对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <string> using namespace std;class Base { public : Base (int i) :m_i (i) {} Base (int i, double j) :m_i (i), m_j (j) {} Base (int i, double j, string k) :m_i (i), m_j (j), m_k (k) {} int m_i; double m_j; string m_k; }; class Child : public Base{ public : using Base::Base; }; int main () Child c1 (520 , 13.14 ) ; cout << "int: " << c1.m_i << ", double: " << c1.m_j << endl; Child c2 (520 , 13.14 , "i love you" ) ; cout << "int: " << c2.m_i << ", double: " << c2.m_j << ", string: " << c2.m_k << endl; return 0 ; }
在修改之后的子类中,没有添加任何构造函数,而是添加了using Base::Base;这样就可以在子类中直接继承父类的所有的构造函数,通过他们去构造子类对象了。
另外如果在子类中隐藏了父类中的同名函数,也可以通过using的方式在子类中使用基类中的这些父类函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <string> using namespace std;class Base { public : Base (int i) :m_i (i) {} Base (int i, double j) :m_i (i), m_j (j) {} Base (int i, double j, string k) :m_i (i), m_j (j), m_k (k) {} void func (int i) { cout << "base class: i = " << i << endl; } void func (int i, string str) { cout << "base class: i = " << i << ", str = " << str << endl; } int m_i; double m_j; string m_k; }; class Child : public Base{ public : using Base::Base; using Base::func; void func () { cout << "child class: i'am luffy!!!" << endl; } }; int main () Child c (250 ) ; c.func (); c.func (19 ); c.func (19 , "luffy" ); return 0 ; }
上述示例代码输出的结果为:
1 2 3 child class : i' am luffy!!! base class : i = 19 base class : i = 19 , str = luffy
子类中的func()函数隐藏了基类中的两个func()因此默认情况下通过子类对象只能调用无参的func()
7. 原始字面量 一个例子直接带入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> #include <string> using namespace std;int main () string str = "D:\hello\world\test.text" ; cout << str << endl; string str1 = "D:\\hello\\world\\test.text" ; cout << str1 << endl; string str2 = R"(D:\hello\world\test.text)" ; cout << str2 << endl; return 0 ; }
1 2 3 D:helloworld est.text D:\hello\world\test.text D:\hello\world\test.text
在R “xxx(raw string)xxx” 中,原始字符串必须用括号()括起来,括号的前后可以加其他字符串,所加的字符串会被忽略,并且加的字符串必须在括号两边同时出现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> #include <string> using namespace std;int main () string str1 = R"(D:\hello\world\test.text)" ; cout << str1 << endl; string str2 = R"luffy(D:\hello\world\test.text)luffy" ; cout << str2 << endl; #if 0 string str3 = R"luffy(D:\hello\world\test.text)robin"; // 语法错误,编译不通过 cout << str3 << endl; #endif return 0; }
1 2 D:\hello\world\test.text D:\hello\world\test.text
结论:使用原始字面量R “xxx(raw string)xxx”,()两边的字符串在解析的时候是会被忽略的,因此一般不用指定。如果在()前后指定了字符串,那么前后的字符串必须相同,否则会出现语法错误。
8. chrono库
C++11中提供了日期和时间相关的库chrono,通过chrono库可以很方便地处理日期和时间,为程序的开发提供了便利。时间间隔duration、时钟clocks、时间点time point。
8.1 时间间隔 8.1.1 常用类成员
duration表示一段时间间隔,用来记录时间长度,可以表示几秒、几分钟、几个小时的时间间隔。
1 2 3 4 5 6 template < class Rep , class Period = std::ratio<1 > > class duration;
1 2 3 4 5 6 template < std::intmax_t Num, std::intmax_t Denom = 1 > class ratio;
ratio类表示每个时钟周期的秒数,其中第一个模板参数Num代表分子,Denom代表分母,该分母值默认为1
为了方便使用,在标准库中定义了一些常用的时间间隔,比如:时、分、秒、毫秒、微秒、纳秒,它们都位于chrono命名空间下,定义如下:
类型
定义
纳秒:std::chrono::nanoseconds
duration<Rep*/*至少 64 位的有符号整数类型*/*, std::nano>
微秒:std::chrono::microseconds
duration<Rep*/*至少 55 位的有符号整数类型*/*, std::micro>
毫秒:std::chrono::milliseconds
duration<Rep*/*至少 45 位的有符号整数类型*/*, std::milli>
秒:std::chrono::seconds
duration<Rep*/*至少 35 位的有符号整数类型*/*>
分钟:std::chrono::minutes
duration<Rep*/*至少 29 位的有符号整数类型*/*, std::ratio<60>>
小时:std::chrono::hours
duration<Rep*/*至少 23 位的有符号整数类型*/*, std::ratio<3600>>
注意:到 hours 为止的每个预定义时长类型至少涵盖 ±292 年的范围。
duration类的构造函数原型如下:
1 2 3 4 5 6 7 8 duration ( const duration& ) = default ;template < class Rep2 >constexpr explicit duration ( const Rep2& r ) template < class Rep2, class Period2 >constexpr duration ( const duration<Rep2,Period2>& d )
为了更加方便的进行duration对象之间的操作,类内部进行了操作符重载:
操作符
描述
operator=
对应复制内容 (公开成员函数)
operator+
实现一元 + 和一元 - (公开成员函数)
operator++
递增或递减周期计数 (公开成员函数)
operator+=
实现二个时长间的复合赋值 (公开成员函数)
duration类还提供了获取时间间隔的时钟周期数的方法count()
1 2 constexpr rep count () const
8.1.2 类的使用
通过构造函数构造事件间隔对象示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <chrono> #include <iostream> using namespace std;int main () chrono::hours h (1 ) ; chrono::milliseconds ms{ 3 }; chrono::duration<int , ratio<1000 >> ks (3 ); chrono::duration<double > dd (6.6 ) ; chrono::duration<double , std::ratio<1 , 30 >> hz (3.5 ); }
h(1)时钟周期为1小时,共有1个时钟周期,所以h表示的时间间隔为1小时ms(3)时钟周期为1毫秒,共有3个时钟周期,所以ms表示的时间间隔为3毫秒ks(3)时钟周期为1000秒,一共有三个时钟周期,所以ks表示的时间间隔为3000秒d3(3.5)时钟周期为1000秒,时钟周期数量只能用整形来表示,但是此处指定的是浮点数,因此语法错误dd(6.6)时钟周期为默认的1秒,共有6.6个时钟周期,所以dd表示的时间间隔为6.6秒hz(3.5)时钟周期为1/30秒,共有3.5个时钟周期,所以hz表示的时间间隔为1/30*3.5秒
chrono库中根据duration类封装了不同长度的时钟周期(也可以自定义),基于这个时钟周期再进行周期次数的设置就可以得到总的时间间隔了(时钟周期 * 周期次数 = 总的时间间隔)。
示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <chrono> #include <iostream> int main () std::chrono::milliseconds ms{3 }; std::chrono::microseconds us = 2 *ms; std::chrono::duration<double , std::ratio<1 , 30 >> hz (3.5 ); std::cout << "3 ms duration has " << ms.count () << " ticks\n" << "6000 us duration has " << us.count () << " ticks\n" << "3.5 hz duration has " << hz.count () << " ticks\n" ; }
输出的结果为:
1 2 3 3 ms duration has 3 ticks6000 us duration has 6000 ticks3.5 hz duration has 3.5 ticks
ms时间单位为毫秒,初始化操作ms{3}表示时间间隔为3毫秒,一共有3个时间周期,每个周期为1毫秒
us时间单位为微秒,初始化操作2*ms表示时间间隔为6000微秒,一共有6000个时间周期,每个周期为1微秒
hz时间单位为秒,初始化操作hz(3.5)表示时间间隔为1/30*3.5秒,一共有3.5个时间周期,每个周期为1/30秒
由于在duration类内部做了操作符重载,因此时间间隔之间可以直接进行算术运算,比如我们要计算两个时间间隔的差值,就可以在代码中做如下处理:
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> #include <chrono> using namespace std;int main () chrono::minutes t1 (10 ) ; chrono::seconds t2 (60 ) ; chrono::seconds t3 = t1 - t2; cout << t3.count () << " second" << endl; }
程序输出的结果:
在上面的测试程序中,t1代表10分钟,t2代表60秒,t3是t1减去t2,也就是60*10-60=540,这个540表示的时钟周期,每个时钟周期是1秒,因此两个时间间隔之间的差值为540秒。
注意:duration的加减运算有一定的规则,当两个duration时钟周期不相同的时候,会先统一成一种时钟,然后再进行算术运算ratio<x1,y1> 和 ratio<x2,y2>两个时钟周期,首先需要求出x1,x2的最大公约数X,然后求出y1,y2的最小公倍数Y,统一之后的时钟周期ratio为ratio<X,Y>。
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> #include <chrono> using namespace std;int main () chrono::duration<double , ratio<9 , 7 >> d1 (3 ); chrono::duration<double , ratio<6 , 5 >> d2 (1 ); chrono::duration<double , ratio<3 , 35 >> d3 = d1 - d2; }
对于分子6,、9最大公约数为3,对于分母7、5最小公倍数为35,因此推导出的时钟周期为ratio<3,35>
8.2 时间点 time point chrono库中提供了一个表示时间点的类time_point,
类的定义如下
1 2 3 4 5 template < class Clock , class Duration = typename Clock::duration > class time_point;
它被实现成如同存储一个 Duration 类型的自 Clock 的纪元起始开始的时间间隔的值,通过这个类最终可以得到时间中的某一个时间点。
Clock:此时间点在此时钟上计量Duration:用于计量从纪元起时间的 std::chrono::duration 类型
time_point类的构造函数原型如下:
1 2 3 4 5 6 7 time_point ();explicit time_point ( const duration& d ) template < class Duration2 >time_point ( const time_point<Clock,Duration2>& t )
在这个类中除了构造函数还提供了另外一个time_since_epoch()函数time_point对象中记录的时间经过的时间间隔(duration)
1 2 duration time_since_epoch () const ;
除此之外,时间点time_point对象和时间段对象duration之间还支持直接进行算术运算(即加减运算),时间点对象之间可以进行逻辑运算,具体细节可以参考下面的表格:
其中 tp 和 tp2 是time_point 类型的对象, dtn 是duration类型的对象。
描述
操作
返回值
复合赋值(成员函数) operator+=
tp += dtn
*this
复合赋值(成员函数) operator-=
tp -= dtn
*this
算术运算符(非成员函数) operator+
tp + dtn
a time_point value
算术运算符(非成员函数) operator+
dtn + tp
a time_point value
算术运算符(非成员函数) operator-
tp - dtn
a time_point value
算术运算符(非成员函数) operator-
tp - tp2
a duration value
关系操作符(非成员函数) operator==
tp == tp2
a bool value
关系操作符(非成员函数) operator!=
tp != tp2
a bool value
关系操作符(非成员函数) operator<
tp < tp2
a bool value
关系操作符(非成员函数) operator>
tp > tp2
a bool value
关系操作符(非成员函数) operator>=
tp >= tp2
a bool value
关系操作符(非成员函数) operator<=
tp <= tp2
a bool value
由于该时间点类经常和下面要介绍的时钟类一起使用,所以在此先不举例
8.3 时钟clocks chrono库中提供了获取当前的系统时间的时钟类,包含的时钟一共有三种:
system_clock:系统的时钟,系统的时钟可以修改,甚至可以网络对时,因此使用系统时间计算时间差可能不准。steady_clock:是固定的时钟,相当于秒表。开始计时后,时间只会增长并且不能修改,适合用于记录程序耗时high_resolution_clock:和时钟类 steady_clock 是等价的(是它的别名)。
在这些时钟类的内部有time_point、duration、Rep、Period等信息,基于这些信息来获取当前时间,以及实现time_t和time_point之间的相互转换。
时钟类成员类型
描述
rep
表示时钟周期次数的有符号算术类型
period
表示时钟计次周期的 std::ratio 类型
duration
时间间隔,可以表示负时长
time_point
表示在当前时钟里边记录的时间点
在使用chrono提供的时钟类的时候,不需创建类对象,直接调用类的静态方法就可以得到想要的时间。
8.3.1 system_clock
具体来说,时钟类system_clock是一个系统范围的实时时钟。system_clock提供了对当前时间点time_point的访问,将得到时间点转换为time_t类型的时间对象,就可以基于这个时间对象获取到当前的时间信息了。
system_clock时钟类在底层源码中的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct system_clock { using rep = long long ; using period = ratio<1 , 10'000'000 >; using duration = chrono::duration<rep, period>; using time_point = chrono::time_point<system_clock>; static constexpr bool is_steady = false ; _NODISCARD static time_point now () noexcept { return time_point (duration (_Xtime_get_ticks())); } _NODISCARD static __time64_t to_time_t (const time_point& _Time) noexcept { return duration_cast <seconds>(_Time.time_since_epoch ()).count (); } _NODISCARD static time_point from_time_t (__time64_t _Tm) noexcept { return time_point{seconds{_Tm}}; } };
通过以上源码可以了解到在system_clock类中的一些细节信息:
rep:时钟周期次数是通过整形来记录的long longperiod:一个时钟周期是100纳秒ratio<1, 10'000'000>duration:时间间隔为rep*period纳秒chrono::duration<rep, period>time_point:时间点通过系统时钟做了初始化chrono::time_point<system_clock>,里面记录了新纪元时间点
另外还可以看到system_clock类一共提供了三个静态成员函数:
1 2 3 4 5 6 static std::chrono::time_point<std::chrono::system_clock> now () noexcept ;static std::time_t to_time_t ( const time_point& t ) noexcept static std::chrono::system_clock::time_point from_time_t ( std::time_t t ) noexcept ;
比如,我们要获取当前的系统时间,并且需要将其以能够识别的方式打印出来,示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <chrono> #include <iostream> using namespace std;using namespace std::chrono;int main () system_clock::time_point epoch; duration<int , ratio<60 *60 *24 >> day (1 ); system_clock::time_point ppt (day) ; using dday = duration<int , ratio<60 * 60 * 24 >>; time_point<system_clock, dday> t (dday(10 )) ; system_clock::time_point today = system_clock::now (); time_t tm = system_clock::to_time_t (today); cout << "今天的日期是: " << ctime (&tm); time_t tm1 = system_clock::to_time_t (today+day); cout << "明天的日期是: " << ctime (&tm1); time_t tm2 = system_clock::to_time_t (epoch); cout << "新纪元时间: " << ctime (&tm2); time_t tm3 = system_clock::to_time_t (ppt); cout << "新纪元时间+1天: " << ctime (&tm3); time_t tm4 = system_clock::to_time_t (t); cout << "新纪元时间+10天: " << ctime (&tm4); }
示例代码打印的结果为:
1 2 3 4 5 今天的日期是: Sun Aug 20 02 :43 :21 2023 明天的日期是: Mon Aug 21 02 :43 :21 2023 新纪元时间: Thu Jan 1 08 :00 :00 1970 新纪元时间+1 天: Fri Jan 2 08 :00 :00 1970 新纪元时间+10 天: Sun Jan 11 08 :00 :00 1970
8.3.2 steady_clock
如果我们通过时钟不是为了获取当前的系统时间,而是进行程序耗时的时长,此时使用syetem_clock就不合适了,因为这个时间可以跟随系统的设置发生变化。
steady_clock时钟类在底层源码中的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct steady_clock { using rep = long long ; using period = nano; using duration = nanoseconds; using time_point = chrono::time_point<steady_clock>; static constexpr bool is_steady = true ; _NODISCARD static time_point now () noexcept { const long long _Freq = _Query_perf_frequency(); const long long _Ctr = _Query_perf_counter(); static_assert (period::num == 1 , "This assumes period::num == 1." ); const long long _Whole = (_Ctr / _Freq) * period::den; const long long _Part = (_Ctr % _Freq) * period::den / _Freq; return time_point (duration (_Whole + _Part)); } };
通过以上源码可以了解到在steady_clock类中的一些细节信息:
rep:时钟周期次数是通过整形来记录的long longperiod:一个时钟周期是1纳秒nanoduration:时间间隔为1纳秒nanosecondstime_point:时间点通过系统时钟做了初始化chrono::time_point<steady_clock>
另外,在这个类中也提供了一个静态的now()方法,用于得到当前的时间点,
1 2 static std::chrono::time_point<std::chrono::steady_clock> now () noexcept ;
假设要测试某一段程序的执行效率,可以计算它执行期间消耗的总时长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <chrono> #include <iostream> using namespace std;using namespace std::chrono;int main () steady_clock::time_point start = steady_clock::now (); cout << "print 1000 stars ...." << endl; for (int i = 0 ; i < 1000 ; ++i) { cout << "*" ; } cout << endl; steady_clock::time_point last = steady_clock::now (); auto dt = last - start; cout << "总共耗时: " << dt.count () << "纳秒" << endl; }
8.3.3 high_resolution_clock
high_resolution_clock提供的时钟精度比system_clock要高steady_clock类的别名。
1 using high_resolution_clock = steady_clock;
因此high_resolution_clock的使用方式和steady_clock是一样的
8.4 转换函数 8.4.1 duration_cast
duration_cast是chrono库提供的一个模板函数,这个函数不属于duration类。修改
1 2 3 template <class ToDuration , class Rep , class Period > constexpr ToDuration duration_cast (const duration<Rep,Period>& dtn)
如果是对时钟周期进行转换:源时钟周期必须能整除目的时钟周期(比如:小时到分钟)。
如果是对时钟周期次数的类型进行转换:低等类型默认可以向高等类型进行转换(比如:int 转 double)。
如果时钟周期和时钟周期次数类型都变了,根据第二点推导(也就是看时间周期次数类型)。
以上条件都不满足,那么就需要使用 duration_cast 进行显示转换。
我们可以修改一下上面测试程序执行时间的代码,在代码中修改duration对象的属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <chrono> using namespace std;using namespace std::chrono;void f () cout << "print 1000 stars ...." << endl; for (int i = 0 ; i < 1000 ; ++i) { cout << "*" ; } cout << endl; } int main () auto t1 = steady_clock::now (); f (); auto t2 = steady_clock::now (); auto int_ms = duration_cast <chrono::milliseconds>(t2 - t1); duration<double , ratio<1 , 1000 >> fp_ms = t2 - t1; cout << "f() took " << fp_ms.count () << " ms, " << "or " << int_ms.count () << " whole milliseconds\n" ; }
示例代码输出的结果:
1 2 3 print 1000 stars .... ************************************************************************************************************* f () took 40.2547 ms, or 40 whole milliseconds
8.4.2 time_point_cast
time_point_cast也是chrono库提供的一个模板函数,这个函数不属于time_point类。转换,因为不同的时间点对象内部的时钟周期Period,和周期次数的类型Rep可能也是不同的,一般情况下它们之间可以进行隐式类型转换,也可以通过该函数显示的进行转换
1 2 3 template <class ToDuration , class Clock , class Duration >time_point<Clock, ToDuration> time_point_cast (const time_point<Clock, Duration> &t) ;
关于函数的使用,示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <chrono> #include <iostream> using namespace std;using Clock = chrono::high_resolution_clock;using Ms = chrono::milliseconds;using Sec = chrono::seconds;template <class Duration >using TimePoint = chrono::time_point<Clock, Duration>;void print_ms (const TimePoint<Ms>& time_point) std::cout << time_point.time_since_epoch ().count () << " ms\n" ; } int main () TimePoint<Sec> time_point_sec (Sec(6 )) ; TimePoint<Ms> time_point_ms (time_point_sec) ; print_ms (time_point_ms); time_point_ms = TimePoint <Ms>(Ms (6789 )); TimePoint<Sec> sec (time_point_ms) ; time_point_sec = std::chrono::time_point_cast <Sec>(time_point_ms); print_ms (time_point_sec); }
注意:关于时间点的转换如果没有没有精度的损失可以直接进行隐式类型转换time_point_cast函数来完成该操作。
9. 静态断言
静态断言static_assert,所谓静态就是在编译时就能够进行检查的断言,使用时不需要引用头文件。静态断言的另一个好处是,可以自定义违反断言时的错误提示信息。
静态断言使用起来非常简单,它接收两个参数:
参数1:断言表达式,这个表达式通常需要返回一个 bool值
参数2:警告信息,它通常就是一段字符串,在违反断言(表达式为false)时提示该信息
一个判断Linux是否为32位平台的小程序
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> using namespace std; int main () static_assert (sizeof (long ) == 4 , "错误, 不是32位平台..." ); cout << "64bit Linux 指针大小: " << sizeof (char *) << endl; cout << "64bit Linux long 大小: " << sizeof (long ) <<endl; return 0 ; }
1 2 3 4 g++ assert.cpp -std=c++11 assert.cpp: In function ‘int main()’: assert.cpp:6:5: error: static assertion failed: 错误, 不是32位平台... static_assert(sizeof(long) == 4, "错误, 不是32位平台..." );
注意 : 由于静态断言的表达式是在编译阶段进行检测,所以在它的表达式中不能出现变量,也就是说这个表达式必须是常量表达式。
10. POD类型 10.1 POD类型 POD是英文中 Plain Old Data 的缩写,翻译过来就是普通的旧数据 。通常用于说明一个类型的属性,尤其是用户自定义类型的属性。
POD属性在C++11中往往是构建其他C++概念的基础
Plain :表示是个普通的类型
Old :体现了其与C的兼容性,支持标准C函数
在C++11中将 POD划分为两个基本概念的合集,即∶平凡的(trivial) 和标准布局的(standard layout )
10.2 “平凡”类型 一个平凡的类或者结构体应该符合以下几点要求:
拥有平凡的默认构造函数(trivial constructor)和析构函数(trivial destructor)。
平凡的默认构造函数就是说构造函数什么都不干。
通常情况下,不定义类的构造函数,编译器就会为我们生成一个平凡的默认构造函数。
一旦定义了构造函数,即使构造函数不包含参数,函数体里也没有任何的代码,那么该构造函数也不再是”平凡”的。
1 2 3 4 class Test1 { Test1 (); };
关于析构函数也和上面列举的构造函数类似,一旦被定义就不平凡了。=default关键字可以显式地声明默认的构造函数,从而使得类型恢复 “平凡化”。
拥有平凡的拷贝构造函数(trivial copy constructor)和移动构造函数(trivial move constructor)。
平凡的拷贝构造函数基本上等同于使用 memcpy 进行类型的构造。
同平凡的默认构造函数一样,不声明拷贝构造函数的话,编译器会帮程序员自动地生成。
可以显式地使用 =default 声明默认拷贝构造函数。
而平凡移动构造函数跟平凡的拷贝构造函数类似,只不过是用于移动语义。
拥有平凡的拷贝赋值运算符(trivial assignment operator)和移动赋值运算符(trivial move operator)。
这基本上与平凡的拷贝构造函数和平凡的移动构造运算符类似。
不包含虚函数以及虚基类。
类中使用 virtual 关键字修饰的函数 叫做虚函数
1 2 3 4 5 6 class Base { public : Base () {} virtual void print () };
虚基类是在创建子类的时候在继承的基类前加 virtual 关键字 修饰
1 语法: class 派生类名:virtual 继承方式 基类名
示例代码:
1 2 3 4 5 6 7 8 9 10 class Base { public : Base () {} }; class Child : virtual public Base { Child () {} };
10.3 “标准布局”类型 标准布局类型主要主要指的是类或者结构体的结构或者组合方式。
标准布局类型的类应该符合以下五点定义,最重要的是前两条:
所有非静态成员有相同 的访问权限(public,private,protected)。
1 2 3 4 5 6 7 8 9 10 class Base { public : Base () {} int a; protected : int b; private : int c; };
1 2 3 4 5 6 7 8 class Base { public : Base () {} int a; int b; int c; };
在类或者结构体继承时,满足以下两种情况之一∶
派生类中有非静态成员,基类中包含静态成员(或基类没有变量)。
基类有非静态成员,而派生类没有非静态成员。
1 2 3 4 5 6 7 8 9 10 struct Base { static int a;};struct Child : public Base{ int b;}; struct Base1 { int a;};struct Child1 : public Base1{ static int c;}; struct Child2 :public Base, public Base1 { static int d;); struct Child3 :public Base1{ int d;}; struct Child4 :public Base1, public Child { static int num; };
结论:
非静态成员只要同时出现在派生类和基类间,即不属于标准布局。
对于多重继承,一旦非静态成员出现在多个基类中,即使派生类中没有非静态成员变量,派生类也不属于标准布局。
子类中第一个非静态成员的类型与其基类不同。
此处基于G++编译器,如果使用VS的编译器和G++编译器得到的结果是不一样的。
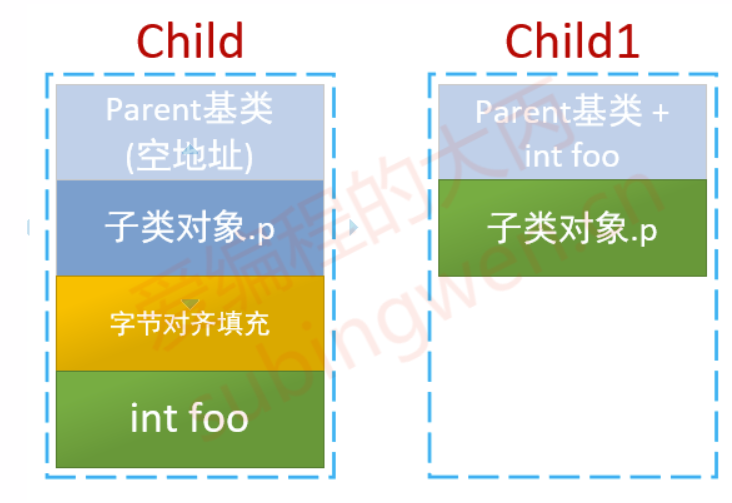
1 2 3 4 5 6 struct Parent {};struct Child : public Parent{ Parent p; int foo; };
上面的例子中Child不是一个标准布局类型
1 2 3 4 5 6 struct Parent {};struct Child1 : public Parent{ int foo; Parent p; };
这条规则对于我们来说是比较特别的,这样规定的目的主要是是节约内存,提高数据的读取效率。对于上面的两个子类Child和Child1来说它们的内存结构是不一样的
没有虚函数和虚基类。
所有非静态数据成员均符合标准布局类型,其基类也符合标准布局,这是一个递归的定义。
10.4 对 POD 类型的判断
如果我们想要判断某个数据类型是不是属于 POD 类型
10.4.1 对“平凡”类型判断 C++11提供的类模板叫做 is_trivial,其定义如下:
1 template <class T > struct std ::is_trivial;
std::is_trivial 的成员value 可以用于判断T的类型是否是一个平凡的类型(value 函数返回值为布尔类型)。is_trivial还可以对内置的标准类型数据(比如int、float都属于平凡类型)及数组类型(元素是平凡类型的数组总是平凡的)进行判断。
关于类型的判断,示例程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <type_traits> using namespace std;class A {};class B { B () {} };class C : B {};class D { virtual void fn () class E : virtual public A { };int main () cout << std::boolalpha; cout << "is_trivial:" << endl; cout << "int: " << is_trivial<int >::value << endl; cout << "A: " << is_trivial<A>::value << endl; cout << "B: " << is_trivial<B>::value << endl; cout << "C: " << is_trivial<C>::value << endl; cout << "D: " << is_trivial<D>::value << endl; cout << "E: " << is_trivial<E>::value << endl; return 0 ; }
输出的结果:
1 2 3 4 5 6 7 is_trivial: int : true A: true B: false C: false D: false E: false
int :内置标准数据类型,属于 trivial 类型
A :拥有默认的构造和析构函数,属于 trivial 类型
B :自定义了构造函数,因此不属于 trivial 类型
C :基类中自定义了构造函数,因此不属于 trivial 类型(继承了B,B自定义了构造函数)
D :类成员函数中有虚函数,因此不属于 trivial 类型
E :继承关系中有虚基类,因此不属于 trivial 类型
10.4.2 对“标准布局”类型的判断 同样,在C++11中,我们可以使用模板类来帮助判断类型是否是一个标准布局的类型
其定义如下:
1 template <typename T> struct std ::is_standard_layout;
通过 is_standard_layout模板类的成员 value(is_standard_layout<T>∶∶value),我们可以在代码中打印出类型的标准布局属性,函数返回值为布尔类型。
示例程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <iostream> #include <type_traits> using namespace std;struct A { };struct B : A { int j; };struct C { public : int a; private : int c; }; struct D1 { static int i; };struct D2 { int i; };struct E1 { static int i; };struct E2 { int i; };struct D : public D1, public E1 { int a; };struct E : public D1, public E2 { int a; };struct F : public D2, public E2 { static int a; };struct G : public A{ int foo; A a; }; struct H : public A{ A a; int foo; }; int main () cout << std::boolalpha; cout << "is_standard_layout:" << std::endl; cout << "A: " << is_standard_layout<A>::value << endl; cout << "B: " << is_standard_layout<B>::value << endl; cout << "C: " << is_standard_layout<C>::value << endl; cout << "D: " << is_standard_layout<D>::value << endl; cout << "D1: " << is_standard_layout<D1>::value << endl; cout << "E: " << is_standard_layout<E>::value << endl; cout << "F: " << is_standard_layout<F>::value << endl; cout << "G: " << is_standard_layout<G>::value << endl; cout << "H: " << is_standard_layout<H>::value << endl; return 0 ; }
VS2019输出的结果
1 2 3 4 5 6 7 8 9 10 is_standard_layout: A: true B: true C: false D: true D1: true E: false F: false G: false H: false
G++ 编译输出的结果:
1 $ g++ pod.cpp -std=c++11
输出的结果
1 2 3 4 5 6 7 8 9 10 is_standard_layout: A: true B: true C: false D: true D1: true E: false F: false G: true H: false
关于输出的结果
A :没有虚基类和虚函数,属于 standard_layout 类型
B :没有虚基类和虚函数,属于 standard_layout 类型
C :所有非静态成员访问权限不一致,不属于 standard_layout 类型
D :基类和子类没有同时出现非静态成员变量,属于 standard_layout 类型
D1 :没有虚基类和虚函数,属于 standard_layout 类型
E :基类和子类中同时出现了非静态成员变量,不属于 standard_layout 类型
F :多重继承中在基类里同时出现了非静态成员变量,不属于 standard_layout 类型
G :使用的编译器不同,得到的结果也不同。
H :子类中第一个非静态成员的类型与其基类类型不能相同,不属于 standard_layout 类型
10.5 总结 我们使用的很多内置类型默认都是 POD的。
字节赋值,代码中我们可以安全地使用 memset 和 memcpy 对 POD类型进行初始化和拷贝等操作。
提供对C内存布局兼容。C++程序可以与C 函数进行相互操作
保证了静态初始化的安全有效。静态初始化在很多时候能够提高程序的性能,而POD类型的对象初始化往往更加简单。
11. 非受限联合体 11.1 什么是非受限联合体 联合体又叫共用体,又将其称之为union,它的使用方式和结构体类似,可以在联合体内部定义多种不同类型的数据成员,但是这些数据会共享同一块内存空间(也就是如果对多个数据成员同时赋值会发生数据的覆盖)。
在C++11之前我们使用的联合体是有局限性的,主要有以下三点:
不允许联合体拥有非POD类型的成员
不允许联合体拥有静态成员
不允许联合体拥有引用类型的成员
在新的C++11标准中,取消了关于联合体对于数据成员类型的限定,规定任何非引用类型都可以成为联合体的数据成员,这样的联合体称之为非受限联合体(Unrestricted Union)
11.2 非受限联合体的使用 11.2.1 静态类型的成员 对于非受限联合体来说,静态成员有两种分别是静态成员变量和静态成员函数
看一下下面代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 union Test { int age; long id; static char c; static int print () { cout << "c value: " << c << endl; return 0 ; } }; char Test::c;int main () Test t; Test t1; t.c = 'b' ; t1.c = 'c' ; t1.age = 666 ; cout << "t.c: " << t.c << endl; cout << "t1.c: " << t1.c << endl; cout << "t1.age: " << t1.age << endl; cout << "t1.id: " << t1.id << endl; t.print (); Test::print (); return 0 ; }
执行程序输出的结果如下:
1 2 3 4 5 6 t.c: c t1.c: c t1.age: 666 t1.id: 666 c value: c c value: c
接下来我们逐一分析一下上面的代码:
11.2.2 非POD类型成员 在 C++11标准中会默认删除一些非受限联合体的默认函数。
举例说明:
1 2 3 4 5 6 7 8 9 10 11 union Student { int id; string name; }; int main () Student s; return 0 ; }
编译程序会看到如下的错误提示:
1 2 warning C4624: “Student”: 已将析构函数隐式定义为“已删除” error C2280: “Student::Student (void )”: 尝试引用已删除的函数
上面代码中的非受限联合体Student中拥有一个非PDO类型的成员string namenew 操作。
placement new
一般情况下,使用new申请空间时,是从系统的堆(heap)中分配空间,申请所得的空间的位置是根据当时的内存的实际使用情况决定的。placement new即定位放置 new。
定位放置new操作的语法形式不同于普通的new操作:
1 ClassName* ptr = new (定位的内存地址)ClassName;
我们来看下面的示例程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> using namespace std;class Base { public : Base () {} ~Base () {} void print () { cout << "number value: " << number << endl; } private : int number; }; int main () int n = 100 ; Base* b = new (&n)Base; b->print (); return 0 ; }
程序运行输出的结果为:
在程序的new部分中,使用定位放置的方式为指针b申请了一块内存,也就是说此时指针 b 指向的内存地址和变量 n对应的内存地址是同一块(栈内存)
最后,总结一下关于placement new的一些细节:
使用定位放置new操作,既可以在栈(stack)上生成对象,也可以在堆(heap)上生成对象,这取决于定位时指定的内存地址是在堆还是在栈上。
从表面上看,定位放置new操作是申请空间,其本质是利用已经申请好的空间,真正的申请空间的工作是在此之前完成的。
使用定位放置new 创建对象时会自动调用对应类的构造函数,但是由于对象的空间不会自动释放,如果需要释放堆内存必须显示调用类的析构函数。
使用定位放置new操作,我们可以反复动态申请到同一块堆内存,这样可以避免内存的重复创建销毁,从而提高程序的执行效率(比如网络通信中数据的接收和发送)。
自定义非受限联合体构造函数
掌握了placement new的使用,通过一段程序演示一下如何在非受限联合体中自定义构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Base { public : void setText (string str) { notes = str; } void print () { cout << "Base notes: " << notes << endl; } private : string notes; }; union Student { Student () { new (&name)string; } ~Student () {} int id; Base tmp; string name; }; int main () Student s; s.name = "蒙奇·D·路飞" ; s.tmp.setText ("我是要成为海贼王的男人!" ); s.tmp.print (); cout << "Student name: " << s.name << endl; return 0 ; }
程序打印的结果如下:
1 2 Base notes: 我是要成为海贼王的男人! Student name: 我是要成为海贼王的男人!
我们在上面的程序里边给非受限制联合体显示的指定了构造函数和析构函数
匿名的非受限联合体
1 2 3 4 进行村内人口普查,人员的登记方式如下: - 学生只需要登记所在学校的编号 - 本村学生以外的人员需要登记其身份证号码 - 本村外来人员需要登记户口所在地+联系方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 struct Foreigner { Foreigner (string s, string ph) : addr (s), phone (ph) {} string addr; string phone; }; class Person { public : enum class Category : char {Student, Local, Foreign}; Person (int num) : number (num), type (Category::Student) {} Person (string id) : idNum (id), type (Category::Local) {} Person (string addr, string phone) : foreign(addr, phone), type (Category::Foreign) {} ~Person () {} void print () { cout << "Person category: " << (int )type << endl; switch (type) { case Category::Student: cout << "Student school number: " << number << endl; break ; case Category::Local: cout << "Local people ID number: " << idNum << endl; break ; case Category::Foreign: cout << "Foreigner address: " << foreign.addr << ", phone: " << foreign.phone << endl; break ; default : break ; } } private : Category type; union { int number; string idNum; Foreigner foreign; }; }; int main () Person p1 (9527 ) ; Person p2 ("1101122022X" ) ; Person p3 ("砂隐村村北" , "1301810001" ) ; p1.print (); p2.print (); p3.print (); return 0 ; }
程序输出的结果:
1 2 3 4 5 6 Person category: 0 Student school number: 9527 Person category: 1 Local people ID number: 1101122022 X Person category: 2 Foreigner address: 砂隐村村北, phone: 1301810001
根据需求我们将木叶村的人口分为了三类并通过枚举记录了下来,在Person类中添加了一个匿名的非受限联合体用来存储人口信息,仔细分析之后就会发现这种处理方式的优势非常明显:
Person类可以直接访问匿名非受限联合体内部的数据成员。
不使用匿名非受限联合体申请的内存空间等于 number、 idNum 、 foreign 三者内存之和。
使用匿名非受限联合体之后number、 idNum 、 foreign 三者共用同一块内存。
12. 强枚举类型 12.1 枚举 12.1.1 枚举的使用 枚举类型是C及C++中一个基本的内置类型,不过也是一个有点”奇怪”的类型。从枚举的本意上来讲,就是要定义一个类别,并穷举同一类别下的个体以供代码中使用。
比如:
1 2 3 4 enum {Red, Green, Blue};enum Colors {Red, Green, Blue};
在枚举类型中的枚举值编译器会默认从0开始赋值,而后依次向下递增,也就是说
12.1.2 枚举的缺陷 C/C++的enum有个很”奇怪” 的设定,就是具名(有名字)的enum类型的名字,以及 enum 的成员的名字都是全局可见的
比如∶
1 2 enum China {Shanghai, Dongjing, Beijing, Nanjing};enum Japan {Dongjing, Daban, Hengbin, Fudao};
上面定义的两个枚举在编译的时候,编译器会报错,具体信息如下:
1 error C2365: “Dongjing”: 重定义;以前的定义是“枚举数”
错误的原因上面也提到了,在这两个具名的枚举中Dongjing是全局可见的,所有编译器就会提示其重定义了。
另外,由于C中枚举被设计为常量数值的”别名”的本性,所以枚举的成员总是可以被隐式地转换为整型,但是很多时候我们并不想这样。
12.2 强类型枚举 12.2.1 优势 针对枚举的缺陷,C++11标准引入了一种新的枚举类型,即枚举类,又称强类型枚举(strong-typed enum)
声明强类型枚举非常简单,只需要在 enum 后加上关键字 class。
1 2 enum class Colors {Red, Green, Blue};
强类型枚举具有以下几点优势∶
强作用域,强类型枚举成员的名称不会被输出到其父作用域空间。
强类型枚举只能是有名枚举,如果是匿名枚举会导致枚举值无法使用(因为没有作用域名称)。
转换限制,强类型枚举成员的值不可以与整型隐式地相互转换。
可以指定底层类型。强类型枚举默认的底层类型为 int,但也可以显式地指定底层类型,
具体方法为在枚举名称后面加上∶type,其中 type 可以是除 wchar_t 以外的任何整型。比如:
1 enum class Colors :char { Red, Green, Blue };
wchar_t 是什么?
双字节类型,或宽字符类型,是C/C++的一种扩展的存储方式,一般为16位或32位,所能表示的字符数远超char型。
了解了强类型枚举的优势之后,看一段程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 enum class China { Shanghai, Dongjing, Beijing, Nanjing, };enum class Japan :char { Dongjing, Daban, Hengbin, Fudao };int main () int m = Shanghai; int n = China::Shanghai; if ((int )China::Beijing >= 2 ) { cout << "ok!" << endl; } cout << "size1: " << sizeof (China::Dongjing) << endl; cout << "size2: " << sizeof (Japan::Dongjing) << endl; return 0 ; }
第5行:该行的代码有两处错误
强类型枚举属于强作用于类型,不能直接使用,枚举值前必须加枚举类型
强类型枚举不会进行隐式类型转换,因此枚举值不能直接给int行变量赋值(虽然强类型枚举的枚举值默认就是整形,但其不能作为整形使用)。
第6行:语法错误,将强类型枚举值作为整形使用,此处不会进行隐式类型转换
第7行:语法正确,强类型枚举值在和整数比较之前做了强制类型转换。
第11行:打印的结果为4,强类型枚举底层类型值默认为int,因此占用的内存是4个字节
第12行:打印的结果为1,显示指定了强类型枚举值的类型为char,因此占用的内存大小为1个字节,这样我们就可以节省更多的内存空间了。
12.2.2 对原有枚举的扩展 相比于原来的枚举,强类型枚举更像是一个属于C++的枚举。
原有枚举类型的底层类型在默认情况下,仍然由编译器来具体指定实现。∶type
1 enum Colors : char { Red, Green, Blue };
关于作用域,在C++11中,枚举成员的名字除了会自动输出到父作用域,也可以在枚举类型定义的作用域内有效。比如:
1 2 3 4 5 6 7 enum Colors : char { Red, Green, Blue };int main () Colors c1 = Green; Colors c2 = Colors::Green; return 0 ; }
上面程序中第4、5行的写法都是合法的。
我们在声明强类型枚举的时候,也可以使用关键字enum struct。enum struct 和 enum class 在语法上没有任何区别(enum class 的成员没有公有私有之分,也不会使用模板来支持泛化的声明 )。
13. Lambda表达式 13.1 语法格式 1 2 3 4 5 6 [capture](params) opt -> ret {body;}; - capture: 捕获列表 - params: 参数列表 - opt: 函数选项 - ret: 返回值类型 - body: 函数体
关于Lambda表达式的细节介绍:
捕获列表: 捕获一定范围内的变量
[] - 不捕捉任何变量[&] - 捕获外部作用域中所有变量, 并作为引用在函数体内使用 (按引用捕获)[=] - 捕获外部作用域中所有变量, 并作为副本在函数体内使用 (按值捕获)
[=, &foo] - 按值捕获外部作用域中所有变量, 并按照引用捕获外部变量 foo[bar] - 按值捕获 bar 变量, 同时不捕获其他变量[&bar] - 按引用捕获 bar 变量, 同时不捕获其他变量[this] - 捕获当前类中的this指针
让lambda表达式拥有和当前类成员函数同样的访问权限
如果已经使用了 & 或者 =, 默认添加此选项
参数列表: 和普通函数的参数列表一样
opt 选项 –> 可以省略
mutable: 可以修改按值传递进来的拷贝(注意是能修改拷贝,而不是值本身)
exception: 指定函数抛出的异常,如抛出整数类型的异常,可以使用throw();
返回值类型:
标识函数返回值的类型,当返回值为void,或者函数体中只有一处return的地方(此时编译器可以自动推断出返回值类型)时,这部分可以省略
函数体:
13.2 定义和调用 因为Lambda表达式是一个匿名函数, 因此是没有函数声明的, 直接在程序中进行代码的定义即可, 但是如果只定义匿名函数在程序执行过程中是不会被调用的。
1 2 3 4 5 6 7 8 9 10 [](){ qDebug () << "hello, 我是一个lambda表达式..." ; }; int ret = [](int a) -> int { return a+1 ; }(100 );
在Lambda表达式的捕获列表中也就是 [] 内部添加不同的关键字, 就可以在函数体中使用外部变量了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int a=100 , b=200 , c=300 ;[](){ qDebug () << "a:" << a << ", b: " << b << ", c:" << c; } [&](){ qDebug () << "hello, 我是一个lambda表达式..." ; qDebug () << "使用引用的方式传递数据: " ; qDebug () << "a+1:" << a++ << ", b+c= " << b+c; }(); [=](int m, int n)mutable { qDebug () << "hello, 我是一个lambda表达式..." ; qDebug () << "使用拷贝的方式传递数据: " ; qDebug () << "a+1:" << a++ << ", b+c= " << b+c; qDebug () << "m+1: " << ++m << ", n: " << n; }(1 , 2 )
*14. 单列模式
这并不属于C++11单独涉及到的区域,只是做一个小补充
一个类只能创建一个对象,即单例模式,该模式可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。
14.1 饿汉模式 特点:
一main函数前就创造对象,程序启动时就创建一个唯一的实例对象
缺点:
由于初始化在main函数之前,这样的类数据过多,会使得启动慢;
多个单例类有初始化依赖关系,饿汉模式无法控制类的初始化先后关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class InfoSingleton { public : static InfoSingleton& GetInstance () { return _sins; } void Insert (string name, int money) { _info[name] = money; } void Print () { for (auto kv : _info) { cout << kv.first << " " << kv.second << endl; } } private : InfoSingleton () {} InfoSingleton (const InfoSingleton& info) = delete ; InfoSingleton& operator =(const InfoSingleton& info) = delete ; map<string, int > _info; private : static InfoSingleton _sins; }; InfoSingleton InfoSingleton::_sins; int main () InfoSingleton::GetInstance ().Insert ("张三" , 1000 ); InfoSingleton& info = InfoSingleton::GetInstance (); info.Insert ("李四" , 100 ); return 0 ; }
14.2 懒汉模式
如果单例对象构造十分耗时或者占用很多资源,比如加载插件,初始化网络连接,读取文件等等,而有可能该对象程序运行时不会用到,那么也要在程序一开始就进行初始化,就会导致程序启动时非常的缓慢。
懒汉模式特点
只创建一次,并且在main函数调用之后创建。
有线程安全问题,C++11可以解决。
饿汉模式不需要注意线程安全问题,在main调用之前就已存在,没有所谓的线程可以创建其他的对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 template <class Lock >class LockGuard { public : LockGuard (Lock& lk) :_lk(lk) { _lk.lock (); } ~LockGuard () { _lk.unlock (); } private : Lock& _lk; }; class _InfoSingleton { public : static _InfoSingleton& GetInstance () { if (_psins == nullptr ) { LockGuard<mutex> lock (*_smtx) ; if (_psins == nullptr ) { _psins = new _InfoSingleton; } } return *_psins; } void Insert (string name, int money) { _info[name] = money; } void Print () { for (auto kv : _info) { cout << kv.first << " " << kv.second << endl; } } private : _InfoSingleton() {} _InfoSingleton(const _InfoSingleton& info) = delete ; _InfoSingleton& operator =(const _InfoSingleton& info) = delete ; map<string, int > _info; private : static _InfoSingleton* _psins; static mutex* _smtx; }; static _InfoSingleton* _psins = nullptr ;static mutex* _smtx;
懒汉模式需要注意线程安全问题,所以我们在类中需要有一个唯一的锁,确保判断时是串行访问
每次都先加锁再进行判断是否为空,非常低效
单例对象释放问题
一般而言单例类不需要释放内存,因为单例出现的环境就是全局的,它的目的就是陪到进程执行到最后,进程结束后,操作系统也会将这一部分的资源回收。
如果有一定要求,我们可以手写出析构